Я пишу код, который выводит синонимы к словам:
from nltk.corpus import wordnet
synonyms = []
for syn in wordnet.synsets("hi"):
for lm in syn.lemmas():
synonyms.append(lm.name())
print (set(synonyms))
Но, данный код выводит синонимы только к английским словам, а как сделать так чтобы выводил и для русских слов?
задан 30 янв 2022 в 6:17
![]()
3
можно перевести так:
from nltk.corpus import wordnet
from deep_translator import GoogleTranslator
synonyms = []
for syn in wordnet.synsets("hi"):
for lm in syn.lemmas():
synonyms.append(lm.name())
rusynonyms = []
for synonym in synonyms:
rusynonyms.append(GoogleTranslator(source='en', target='ru').translate(synonym))
print(rusynonyms)
ответ дан 30 янв 2022 в 8:17
![]()
АкмальАкмаль
3351 золотой знак2 серебряных знака10 бронзовых знаков
4

Last update: Dec 14, 2022
ru_synonyms
Russian words synonyms and antonyms.
Install
pip install git+https://github.com/ahmados/rusynonyms.git
Usage
from ru_synonyms import AntonymsGraph, SynonymsGraph
# Initialize both synonyms and antonyms graph
sg = SynonymsGraph()
ag = AntonymsGraph()
# Sample input word
word = "хорошо"
# Check whether word in graph or not.
assert sg.is_in_dictionary(word)
# Print first found synonym
print(next(sg.get_list(word)))
# Check whether word in graph or not.
assert ag.is_in_dictionary(word)
# Print first found antonym
print(next(ag.get_list(word)))
>> впору
>> нет
Что?
Это кастомные классы и два adjlist файла для извлечения синонимов и антонимов слов русского языка. Прошу упоминать репозиторий и автора если будете использовать эти ресурсы.
Автор
Sumekenov Akhmad, [email protected], t.me/sumekenov
Finetuned by Artem Gribul
Update 07.12
Included package data in setup.py, otherwise not working

The projects lets you extract glossary words and their definitions from a given piece of text automatically using NLP techniques
Unsupervised technique to Glossary and Definition Extraction Code Files GPT2-DefinitionModel.ipynb — GPT-2 model for definition generation. Data_Gener
Words_And_Phrases — Just a repo for useful words and phrases that might come handy in some scenarios. Feel free to add yours
Words_And_Phrases Just a repo for useful words and phrases that might come handy in some scenarios. Feel free to add yours Abbreviations Abbreviation
Write Alphabet, Words and Sentences with your eyes.
The-Next-Gen-AI-Eye-Writer The Eye tracking Technique has become one of the most popular techniques within the human and computer interaction era, thi
Yomichad — a Japanese pop-up dictionary that can display readings and English definitions of Japanese words
Yomichad is a Japanese pop-up dictionary that can display readings and English definitions of Japanese words, kanji, and optionally named entities. It is similar to yomichan, 10ten, and rikaikun in spirit, but targets qutebrowser.
Twitter Sentiment Analysis using #tag, words and username
Twitter Sentment Analysis Web App using #tag, words and username to fetch data finds Insides of data and Tells Sentiment of the perticular #tag, words or username.
Correctly generate plurals, ordinals, indefinite articles; convert numbers to words
NAME inflect.py — Correctly generate plurals, singular nouns, ordinals, indefinite articles; convert numbers to words. SYNOPSIS import inflect
p = in
Get list of common stop words in various languages in Python
Python Stop Words Table of contents Overview Available languages Installation Basic usage Python compatibility Overview Get list of common stop words
Correctly generate plurals, ordinals, indefinite articles; convert numbers to words
NAME inflect.py — Correctly generate plurals, singular nouns, ordinals, indefinite articles; convert numbers to words. SYNOPSIS import inflect
p = in
Get list of common stop words in various languages in Python
Python Stop Words Table of contents Overview Available languages Installation Basic usage Python compatibility Overview Get list of common stop words
-
Do some refactoring
I’ve done some refactoring, merge it if you find it useful =)
Changelist:
- Now abstract class LexicaGraph is really abstract, and named
LexicalGraphInterface. - Reworked docstring style (to Google docstring style).
- Reworked typing (e.g.
List[str]->Iterator[str], because the methods of the abstract class actually returns iterator). - Reworked graph initialization for
SynonymsGraphandAntonymsGraph(I’m a fan of using pathlib module instead of os.path) - Added setup.py and requirements.txt for easy installation.
- Reworked readme.md (added installation guide and usage example)
opened by Datasciensyash 1
- Now abstract class LexicaGraph is really abstract, and named
Компьютеры понимают только числа. Чтобы обучить машину естественному (человеческому) языку, мы должны перевести все слова в числовой формат. Для этого можно использовать встраивание слов — Word2Veс.

Вместе с Марией Обедковой, NLP Engineer в TrustYou, разбираемся, как работает Word2Vec (на примере Python-библиотеки Gensim).
Как превратить текст в числа
Обработка естественного языка (NLP) начинается с преобразования текста в числа — векторизации. Текст разбивают на части (токены) — символы, слова или предложения, — а затем присваивают числовое значение каждой части (в зависимости от частоты, с которой токен встречается в тексте). Токену можно назначить не одно число, а вектор, состоящий из нескольких чисел.
Word2Vec — одна из реализаций предварительно обученного векторного представления слов от Google.
Создавать векторы можно с помощью подходов One-Hot Encoding и Embedding. В One-Hot Encoding каждый вектор состоит из количества чисел, совпадающего с числом слов в тексте. Все элементы вектора равны 0, кроме того, который соответствует токену.
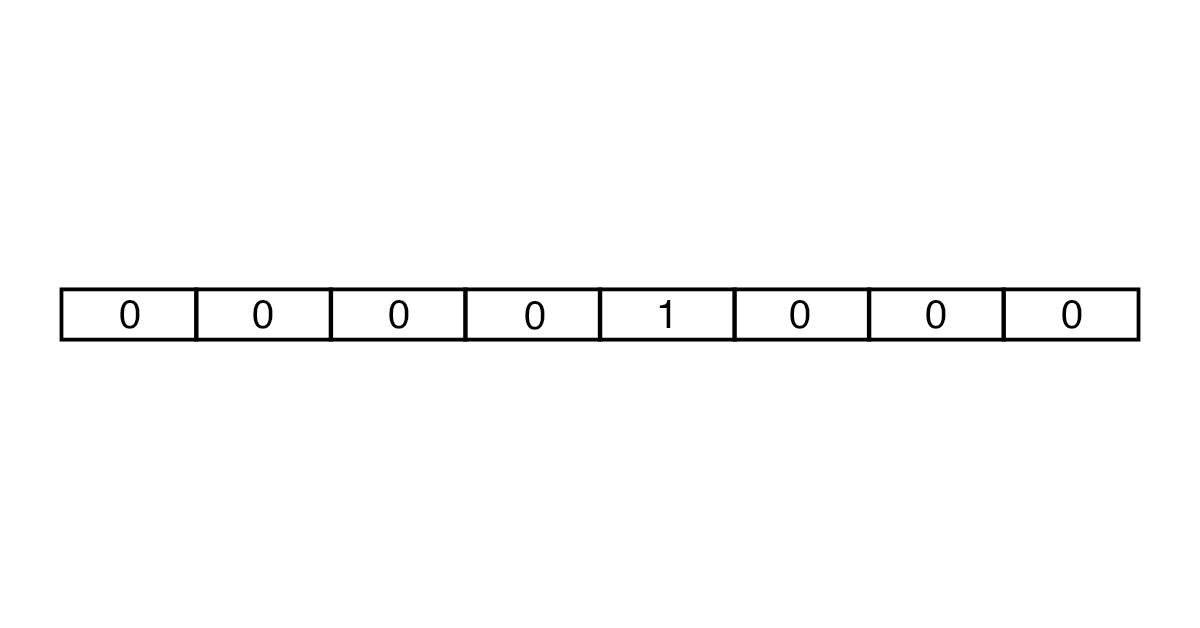
Сначала количество слов для анализа ограничивается с помощью словарей. Для английского языка, например, используют словари Oxford 3000 и Merriam-Webster. Затем создается вектор нужной длины из множества нулей и одной единицы. В итоге получаются векторы большого размера, которые занимают много места в памяти.
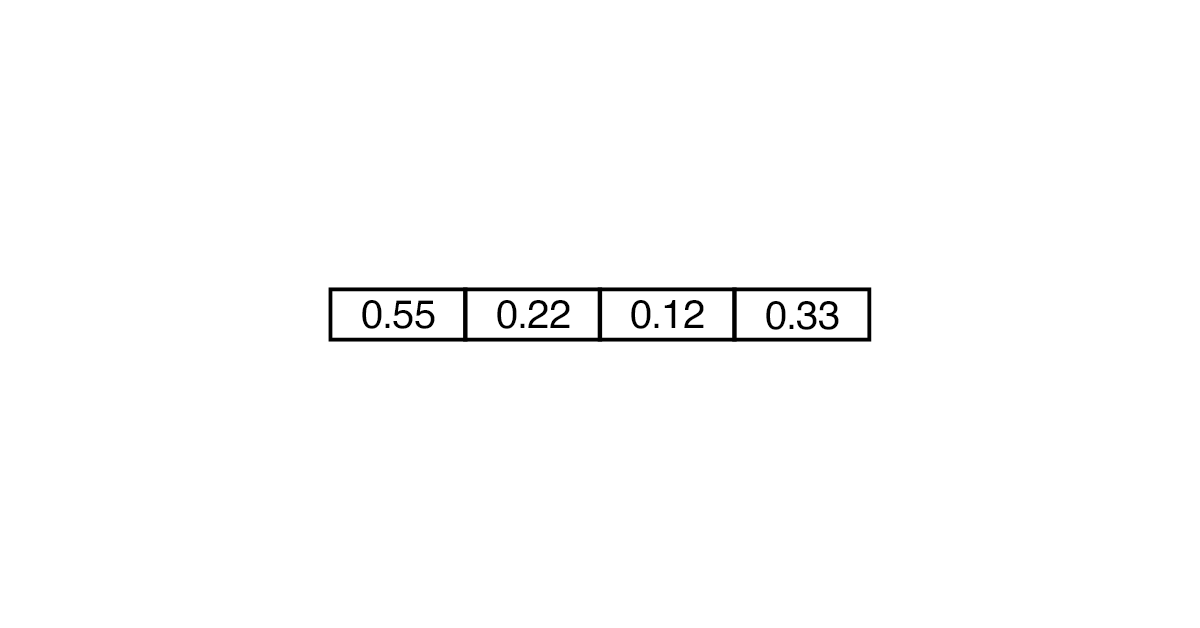
Embedding считается более эффективным и менее ресурсоемким. В таком случае вектор может состоять не только из 0 и 1, но и из других чисел. Понадобится меньше «ячеек», чтобы преобразовать слово.
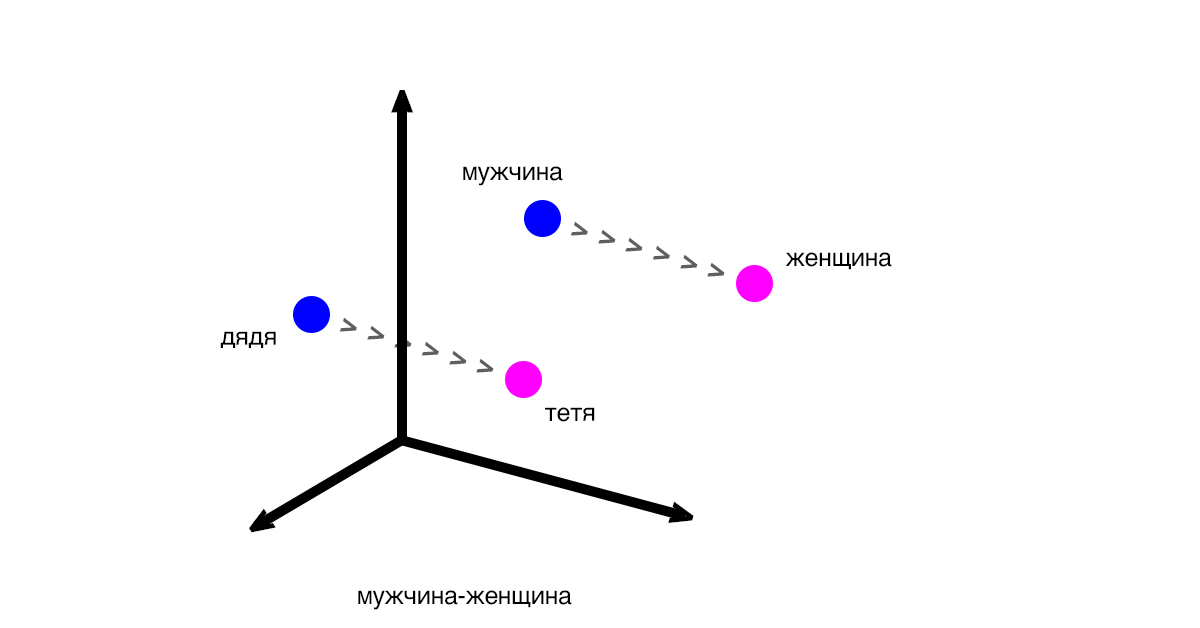
Векторы показывают разницу и закономерности между частями текста (словами, предложениями). Классический пример: вектор между словами «мужчина» и «женщина» будет таким же, как и вектор между словами «дядя» и «тетя».
Расстояния между векторами соответствуют смыслу слов. Выражение «дядя» — «мужчина» + «женщина» будет близким к «тетя», но при этом может не соответствовать ему на 100%.
Мария: «Word2Vec используют как основу для больших проектов и как способ решения исследовательских подзадач. При этом у идеи дистрибутивной семантики (того, что слово можно идентифицировать по контексту) есть недостатки. Например, схожесть слов не всегда указывает на то, что они одинаковы по смыслу».
Поиск синонимов: пишем скрипт
Для работы с Word2Vec можно использовать библиотеку Gensim. Она помогает обрабатывать естественные языки и извлекать семантические темы из документов. Gensim «перегоняет» текст в вектор и считает расстояние между векторами. Преимущество библиотеки в том, что она не требует полной загрузки корпуса в память, а позволяет читать данные с диска.
Рассказываем на примере, как векторные представления помогают находить синонимы для улучшения работы поисковых запросов.
- 1. Загрузим библиотеки для парсинга и анализа страниц.
pip install beautifulsoup4 pip install lxml - 2. Приступим к написанию скрипта и подтянем необходимые зависимости (для парсинга, работы с регулярными изображениями, NLP и Gensim).
import bs4 as bs import urllib.request import re import nltk from nltk.corpus import stopwords from gensim.models import Word2Vec - 3. Будем парсить страницу «Википедии» о романе Филипа Дика Do Androids Dream of Electric Sheep.
scrapped_data = urllib.request.urlopen('https://en.wikipedia.org/wiki/Do_Androids_Dream_of_Electric_Sheep') article = scrapped_data.read() - 4. С помощью объекта BeautifulSoup извлекаем из абзацев текст.
parsed_article = bs.BeautifulSoup(article, 'lxml') paragraphs = parsed_article.find_all('p') - 5. Объединяем весь текст в переменной article_text.
article_text = "" for p in paragraphs: article_text += p.text - 6. Дальнейшая работа любого скрипта зависит от того, насколько хорошо вы провели очистку исходного текста. Поэтому мы переводим все символы в нижний регистр.
cleaned_article = article_text.lower() - 7. Оставляем только буквы и убираем пробелы, используя регулярные выражения.
cleaned_article = re.sub('[^a-z]', ' ', cleaned_article) cleaned_article = re.sub(r's+', ' ', cleaned_article) - 8. Готовим датасет для обучения.
all_sentences = nltk.sent_tokenize(cleaned_article) all_words = [nltk.word_tokenize(sent) for sent in all_sentences] - 9. Проходимся по датасету и удаляем стоп-слова (те, которые не добавляют смысла, например, is).
for i in range(len(all_words)): all_words[i] = [w for w in all_words[i] if w not in stopwords.words('english')] - 10. Создаем модель Word2Vec со словами, чаще всего встречающимися в тексте. Например, теми, которые встречаются минимум 3 раза (min_count=3).
word2vec = Word2Vec(all_words, min_count=3) - 11. В рамках модели находим и выводим самое близкое по смыслу (topn=1) слово для book.
print(word2vec.wv.most_similar('book', topn=1))
Готово — ближайший синоним слова book по нашему словарю — novel.
[(‘novel’, 0.26558035612106323)]
Таким же образом можно искать близкие значения к отдельным словам и целым запросам.

Существует множество сервисов по подбору синонимов, но они редко справляются с терминами, которые содержат в себе более одного слова. Для подбора синонимов для более сложных выражений могут помочь Викиданные.
Мало кто знает, что помимо стандартной Википедии существует дополнительная база данных Викиданные(Wikidata), которая представляет собой граф знаний фонда Викимедия. Сейчас она интегрирована в саму Википедию, поэтому для многих статей в левом меню можно найти пункт Элемент Викиданных. Викиданные представлены в модели RDF, то есть информация имеет вид триплетов, которые характеризуют сущность. Триплет выглядит, как утверждение субьект — предикат — обьект. Пример, для сущности Англия одним из таких информационных триплетов представлен: Англия — имеет столицу — Лондон.
Один из предикатов(типов связи) это altLabel, подразумевающий под собой альтернативные названия, который как раз таки и поможет нам в поиске синонимов.
Сразу стоит учитывать, что Викиданные это очень обширная база знаний, но, тем не менее, не совершенная. Поэтому, для терминов, которые там не представлены, или представлены, но для их сущностей нет введенных альтернативных названий, синонимов найдено не будет.
Поиск элемента в базе знаний
В первую очередь нужно найти сущность викиданных, представляющую данный термин. Для этого нужно найти его уникальный идентификатор(Q_id). Это можно сделать послав запрос через Wikidata API.
Полную документацию на API можно найти на https://www.mediawiki.org/wiki/API:Main_page
import requests
session = requests.Session()
URL = 'https://www.wikidata.org/w/api.php'
def wbgetentities(name):
res = session.post(URL, data={
'action': 'wbsearchentities',
'search': name,
'language':'ru',
'format': 'json',
})
try:
res_json = res.json()['search'][0]['id']
except:
res_json = None
return res_json
Q_id = wbgetentities(term)Поиск синонимов
Для поиска синонима используем SPARQL. SPARQL это язык запросов к данным RDF, который позволяет быстро искать данные по запросу. Он позволит нам выполнить поиск альтернативных названий для нашей сущности по предикату altLabel.
Для отправки запросов sparql была использована библиотека sparql-client.
import sparql
def create_query(first_id):
q = ('''
PREFIX entity: <http://www.wikidata.org/entity/>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
SELECT ?syno
WHERE {
?O ?P ?id .
OPTIONAL{?id skos:altLabel ?syno
filter (lang(?syno) = 'ru')}
VALUES ?id {entity:'''+ first_id +'''}
SERVICE wikibase:label {bd:serviceParam wikibase:language "ru" .}}''')
return q
synonyms = []
query = create_query(Q_id)
result = sparql.query('https://query.wikidata.org/sparql', query)
for r in result:
values = sparql.unpack_row(r)
if values[0] not in synonyms:
synonyms.append(values[0])
print(synonyms)Таким образом, код выдаст список синонимов для термина, если они есть в системе Викиданных. Так же можно найти синонимы на другом языке, если поменять в запросе код ‘ru’ на код другого языка, представленного в списке https://www.wikidata.org/wiki/Help:Wikimedia_language_codes/lists/all
На чтение 4 мин Просмотров 2.6к. Опубликовано 15.02.2021
Рассмотрим инструменты и возможности обработки естественного языка библиотекой TextBlob в языке программирования Python.
Содержание
- Введение
- Библиотеки NLP в Python
- Исправление ошибок в орфографии
- Извлечение существительного из предложений
- Сентиментальный анализ
- Поиск синонимов слов
- Поиск синонимов слова
- Определение языка и перевод текста
Введение
NLP (Natural Language Processing) — это подмножество ИИ (искусственный интеллект), которое позволяет компьютерам понимать, интерпретировать и манипулировать человеческими естественными языками.
История НЛП началась в начале 1950-х годов (хотя работы можно найти и в более ранние периоды), когда Алан Тьюринг, человек, оказавший существенное влияние на развитие информатики, опубликовал статью под названием «Компьютерная техника и интеллект», в которой предложил критерий интеллекта, который теперь известен как тест Тьюринга.
Библиотеки NLP в Python
NLP содержит много интересных библиотек, самой базовой из которых является NLTK (Natural Language Toolkit), эта библиотека довольно универсальна, но также довольно сложна в использовании. В большинстве случаев она довольно медленная и не соответствует требованиям быстро развивающегося производства. Другие известные библиотеки:
- TextBlob
- CoreNLP
- Polyglot
- SpaCy
- Gensim
Из всех этих библиотек, которые я упомянул, TextBlob — мой личный фаворит. Он в основном предоставляет новичкам простой интерфейс, который поможет им освоить большинство основных задач NLP, таких как анализ настроений, POS-tagging или извлечение именных фраз.
Давайте рассмотрим некоторые из них прямо сейчас.
Исправление ошибок в орфографии
Часто люди склонны делать много опечаток. В этом случае библиотека TextBlob может очень пригодиться давайте посмотрим на программу чтобы увидеть как она работает:
from textblob import TextBlob text = "hi my namee is joohn i lik to reead bookz" out = TextBlob(text).correct() print(out)
Вывод программы
hi my name is john i like to read book
В приведенной выше программе я сначала импортировал библиотеку, а затем написал предложение, содержащее много неправильных слов, после чего я просто вызвал правильную функцию библиотеки и, наконец, получил вывод.
Извлечение существительного из предложений
Всякий раз когда мы хотим сделать некоторые манипуляции с естественным языком с помощью компьютера, мы обычно должны извлечь много вещей из предложения, например, одна важная вещь — это извлечение существительных, и TextBlob идеально подходит для этой задачи тоже:
from textblob import TextBlob
nouns = TextBlob(
"The United Arab Emirates' Hope spacecraft entered Mars orbit last week and already sent a simply dazzling image of the red planet."
)
for noun in nouns.noun_phrases:
print(noun)
Вывод программы
arab emirates hope mars red planet
Сентиментальный анализ
Сентиментальный анализ — это процесс вычислительной идентификации и категоризации мнений, выраженных в тексте, особенно для того, чтобы определить, является ли отношение автора к определенной теме, продукту и так далее положительным, отрицательным или нейтральным. Это используется всеми компаниями по всему миру, чтобы получить отзыв о своей продукции.
from textblob import TextBlob
from textblob.sentiments import NaiveBayesAnalyzer
text_one = TextBlob(
"The weather is sunny and warm ",
analyzer=NaiveBayesAnalyzer(),
)
text_two = TextBlob(
"The weather is rainy and cold ",
analyzer=NaiveBayesAnalyzer(),
)
print(text_one.sentiment)
print(text_two.sentiment)
Вывод программы
Sentiment(classification='pos', p_pos=0.7961782042319571, p_neg=0.20382179576804146) Sentiment(classification='neg', p_pos=0.4041799799704329, p_neg=0.5958200200295667)
Поиск синонимов слов
Всякий раз, когда я хочу узнать антоним слова, я либо ищу это слово в словаре (старая школа), либо ищу его в Интернете, но задумывались ли вы когда-нибудь, как онлайн-поиск может ответить на ваши запросы, да, они также используют для этого NLP, и TextBlob снова может помочь нам сделать то же самое:
from textblob import Word
text = Word("sweet")
antonyms = set()
for synset in text.synsets:
for lemma in synset.lemmas():
if lemma.antonyms():
antonyms.add(lemma.antonyms()[0].name())
print(antonyms)
Вывод программы
Поиск синонимов слова
Точно так же, как я могу найти антоним, я также могу найти синоним, но позвольте мне рассказать вам еще об одном интересном аспекте этой библиотеки, который заключается в том, что она также может определить слово для вас, просто набрав одно дополнительное утверждение.
from textblob import Word as W
keyword = W("python")
syn = set()
for s in keyword.synsets:
for l in s.lemmas():
syn.add(l.name())
print(syn)
Вывод программы
{'sire', 'mother', 'overprotect', 'fuss', 'generate', 'female_parent', 'engender', 'father', 'get', 'beget', 'bring_forth'}
Определение языка и перевод текста
Это, безусловно, лучшая часть этой библиотеки, и я сделал свой собственный переводчик языка и детектор приложений с помощью библиотеки TextBlob.
from textblob import TextBlob
text = TextBlob("Меня зовут Егор")
print(text.detect_language())
print(text.translate(to="en"))
print(text.translate(to="fr"))
Вывод программы
ru My name is Egor Je m'appelle Egor
Я надеюсь, что теперь у вас есть представление о том, насколько мощны библиотеки NLP. Надеюсь, сегодня вы узнали что-то новое! Удачной разработки.