
В этой статье я расскажу как максимально правильно оптимизировать URL под поисковые системы. Используя советы ниже вы сможете сделать URL страниц полезными и правильными для SEO продвижения.
Старайтесь использовать только один домен или поддомен.
Проводя практические исследования по перемещению контента С домена на поддомен и в обратную сторону было выявлено что при перемещение контента на основной домен позиции стремительно росли. Но если, перемещение контента делали в обратном порядке, то позиции значительно ухудшались сразу, а рост был очень медленным, даже при условии полной и правильной внешней и внутренней оптимизации.
Если подумать логически, подобна ситуация возникает из-за того что поисковые системы намного лояльнее относятся к основному домену чем большому количеству поддоменов на одном домене.
Кроме того на одном домене будет легче накопить вес и сделать внешнюю оптимизацию.
Некоторые движки сайтов в структуре сайта используют повторяющиеся значения в URL, иногда это делают вебмастера надеясь на то что повторение ключевых слов в URL поможет лучше ранжироваться страницам. На сам деле все совсем наоборот поисковые системы и пользователи могут счесть такие URL как за спамные. Пример:

Повторение ключевых слов в URL
Не стоит добавлять слишком много ключевых слов в URL что бы не получить санкции поисковых систем.
Лучший разделить слов в URL это дефис.
Если прочитать документацию Google для вебмастеров (применимо и к Яндексу), можно узнать что самым удобным разделителем слов в URL это обычный дефис. Естественно писковые системы легко понимают и другие разделители, даже пробел, только в URL он будет выглядеть как «%20». Согласитесь такой формат будет не очень удобочитаемым и дружелюбным по отношению к пользователям.
Используйте только нижний регистр в URL.
Хостинг сайта может быть организован на серверах к примеру, Microsoft или UNIX/Linux. данные хостинги будут по разному воспринимать регистр букв в URL. Хостинг на базе Microsoft с легкостью отличит URL site.ru/OnePage и site.ru/onepage , а если вас хостинг будет на базе Linux/UNIX, то страница site.ru/OnePage может быть не найдена из-за двух букв верхнего регистра. Пример:

URL с разным регистром букв
Если вы уже наломали дров с регистром, вы можете настроить серверный 301 редирект с неправильных URL на URL с нижним регистром.
Откажитесь от использования хешей, # в URL.
На длинных страницах многие используют якоря # что бы быстро переместится на конкретную часть страницы. Если ссылка содержит хеш, то она определятся как отдельная ссылка на отдельный контент. Но на самом деле это не так, мы просто быстро попадаем на нужную часть страницы. после отказа от хешей на таких крупных сайтах как Twitter и Amazon, в разы улучшили свою производительность получчив еще большую лояльность поисковых систем. если у вас есть возможность отказаться полностью от хешей в URL, сделайте это.
Сократите длину URL, уменьшите уровни вложенности.
К примеру возьмем такой URL:
spirtnoe.ru/index/ireland/whiskeys/midleton/25-year/750ml
и сократите его до такого:
spirtnoe.ru/whiskeys/midleton-25-year-750ml
Мы изменили уровень вложенности, сделали URL удобочитаемым для пользователей. Это позитивно скажется на индексировании сайта, а также увеличении качества поведенческих факторов.
В итоге, чем короче URL, тем лучше. Не доходите до крайности, если URL короче 50-60 символов, это нормально. Но если он длиннее сотни, то лучше его сократить.
Google или Яндекс нормально обрабатывают длинные URL. Дело больше в юзабилити. Короткие URL легче понимать, копировать, вставлять, ими легче поделиться. Это может казаться маленьким улучшением, но каждый твит, лайк, email и ссылка имеют значение (прямо или чаще косвенно).
Не делайте цикличных и длинных редиректов.
Если количество редиректов с одной страницы на другую более двух, то это негативно скажется на ранжировании страниц. Чем больше поисковому роботу или пользователю нужно сделать скачков по URL, тем меньший интерес будет к контенту страницы. В таком случае поисковые боты не проиндексируют конечную страницу, а пользователь в ожидании контента может закрыть сайт.
Есть вариант когда редирект получается цикличным или замкнутым. Это приводит к тому что боты и люди попадают на URL которые редиректят друг на друга. Это приводит к тому что не пользовательно не поисковой бот не могут найти нужную страницу. старайтесь не допустить подобных редиректов на вашем проекте.
Удаляйте из URL символы и знаки препинания и пунктуации.
Все эти символы и знаки являются мусорными и совершенно не нужны в нормальном URL. Такие знаки и символы мешают понимать URL правильно, некоторые поисковые боты не могут работать нормально если в URL содержатся подобные знаки.
Убирайте стоп слова из URL.
Хорошим методом сокращения длинны URL является исключение стоп слов из URL. Поисковые системы не учитывают стоп слова в URL. Это сделает ваш URL более релевантным для поисковых систем.
Делайте URL страниц схожими на заголовки.
Я думаю что вы уже знаете что заголовок страницы является одним из самых важных элементов ранжирования страницы. Если ваш заголовок будет соответствовать или похож на URL страницы то это добавит еще несколько балов к ранжированию страницы. Пример:

Правильный URL из заголовка
Используйте человеко понятные URL (ЧПУ).
Дружественные URL (ЧПУ) – это интерпретация адресов страниц в удобном виде для человека. Например, сейчас адрес страницы выглядит следующим образом http://site.com/index.php?q=1. Пример:

Непонятный человеку URL
Данный формат удобен для роботов и разработчиков, но не для обычных посетителей. Приведя адрес к виду http://site.com/directory/simple.html можно понять содержимое страницы не заходя на неё. Кроме того, использование траслитерированных ключевых слов в адресе страницы является еще одним положительным элементом для ранжирования страницы в поисковой выдаче.
Структура URL должна формироваться следующим образом:
Главная + [раздел]
Главная + [раздел] + [подраздел]
Главная + [раздел] + [подраздел] + [страница]
При настройке ЧПУ следует придерживаться нескольких простых правил:
- Для формироавния URL необходимо использовать транслитирированные ключевые слова в точности соответствующие содержимому страницы;
- Синтаксис формирования адресов страниц должен быть единым для всего сайта;
- В адресах страниц следует использовать только строчные латинские символы, не кириллицу;
- При формирования URL для русскоязычных сайтов следует использовать транслитерацию.
- В качестве разделителя слов в URL следует использовать знак минус «-».
Избавьтесь от дублей страниц с разными URL.
Многие CMS генерируют множество страниц с одним и тем же контентом но разными URL. Например:
- site.ru
- site.ru/index.php
- site.ru/index.html
- site.ru/index.xhtml
- site.ru/index.htm
- site.ru/page-1
- site.ru/page-1/
Все эти URL, это одна и та же главная страница сайта. Поисковые системы могут считают такие страницы дублями. Это может вызвать наложение фильтров на сайт. Такие страницы можно закрыть от индексации, отредиректить на главную, настроить rel=canonical. избегайте дублирования одной страницы под разными URL.
Используйте ключевые слова в URL.
Как я уже писал выше главное с этим не переборщить. Ключевые слова в URL играют огромную роль при ранжировании страницы, самое главное не делайте спамных УРЛов.
В данной статье мы рассмотрим работу механизма тегов.
- Для чего нужен механизм тегов
- Как создать товарный тег
Внимание
Функционал доступен с тарифного плана «Профи».
Для чего нужен механизм тегов
Для магазинов на платформе AdvantShop имеется возможность создавать виртуальные категории товаров, которым присвоены определенные метки (теги).
Рассмотрим работу этого функционала на примере.
Допустим у вас есть категория товаров «Телевизоры», в которую загружено 1000 товаров. Используя фильтрацию по свойствам товаров, клиент сможет найти нужный ему товар. Но при этом поисковая система проиндексирует категорию «Телевизоры» как одну страницу и вы не сможете оптимизировать её под разные поисковые запросы.
Конечно, можно разбить категорию «Телевизоры» на подкатегории и тогда частично задача будет решена. А функционал тегов позволяет делать эти категории виртуальными, причём их количество ничем не ограничено.
Если для SEO-оптимизации вам нужна категория «3D телевизоры Samsung белого цвета с функцией SmartTV» — вы можете собрать в одной такой виртуальной категории нужные товары.
Как создать товарный тег
1. Перейдите в раздел «Настройки» — «Товары» (рис. 1), затем — на вкладку «Теги» (рис.2)
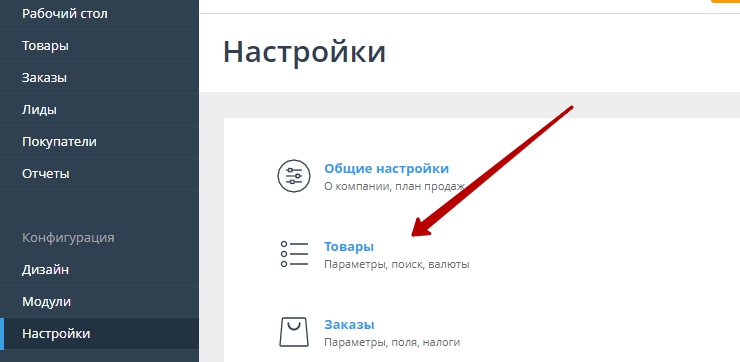
Рисунок 1.
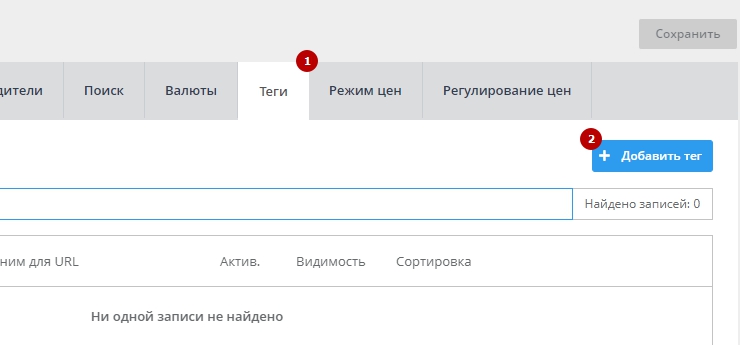
Рисунок 2.
2. Нажмите на кнопку «Добавить тег»
3. На открывшейся странице создания тега введите название тега, синоним для URL запроса и описания при необходимости (рис. 3, 4)
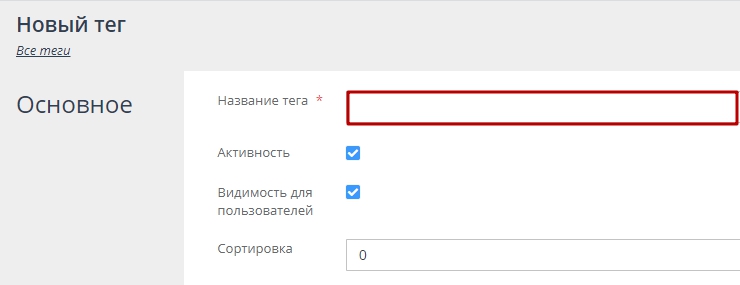
Рисунок 3.
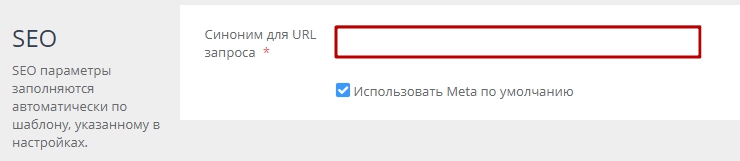
Рисунок 4.
4. SEO настройки.
Есть два варианта:
а) Использование SEO настроек по умолчанию (рис. 5). В этом случае будут использоваться SEO настройки по умолчанию из меню «Настройки» — «SEO и счетчики».
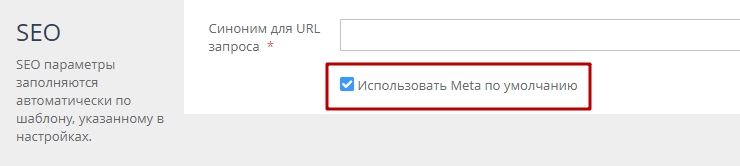
Рисунок 5.
б) Использование уникальных SEO настроек. Для этого снимите галочку «Использовать Meta по умолчанию» и укажите необходимые настройки (рис. 7). Вы можете использовать переменные #STORE_NAME# (название магазина) и #TAG_NAME# (название тега).
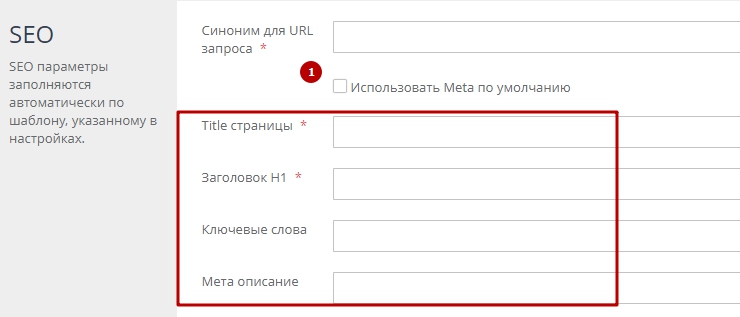
Рисунок 6.
5. Нажмите кнопку «Сохранить».
6. После того как виртуальная категория (тег) создана, нужно добавить в нее товары. Это делается вручную для каждого товара или массово через CSV файл.
Вручную тег можно добавить в редактировании товара. Необходимо начать вводить название тега в поле «Теги» — платформа сама предложит вам вариант из существующих тегов (рис. 9)
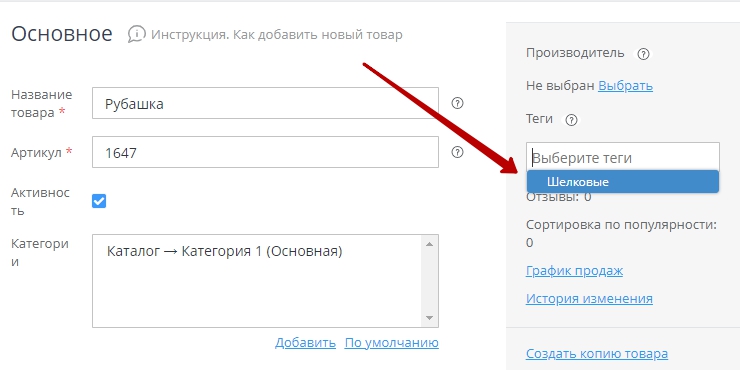
Рисунок 7.
В поле «Теги» можно ввести и несколько тегов.
Теперь, как мы видим, товар привязан к тегу. Нажмите на кнопку «Сохранить» (рис. 8).
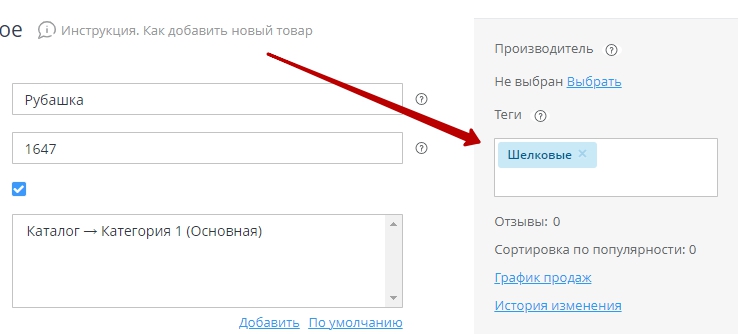
Рисунок 8.
7. Следующий шаг — привязка тега к категории, в которой он будет виден для пользователя. Перейдите в редактирование категории, в который находится ранее редактируемый товар (рис. 11).

Рисунок 9.
Добавьте тег в поле «Теги» (аналогично тому, как вы делали это в пункте 6) и нажмите кнопку «Сохранить».
8. В клиентской части в категории над товарами появится кнопка тега (рис. 10). Пользователи смогут нажать её. Также, поисковая система сможет проиндексировать страницу тега, открывающуюся по этой кнопке.
Рисунок 10.
9. Нажав на кнопку тега, мы попадём на страницу, где будут представлены все товары с этим тегом, которые находятся в этой категории (рис. 11)
Рисунок 11.
SEO-настройки для этой страницы будут браться из настроек тега, а URL страницы будет выглядеть так: site.ru/categories/apple-phones/tag/test. То есть, к URL категории добавится элемент /tag/ и URL-синоним тега.
В итоге получилась страница со своими SEO-настройками, на которой выводятся назначенные вами товары. Такую страницу можно продвигать под конкретные поисковые запросы.
Базовый функционала для сайта сделан, все приведено к более-менее подобающему виду. Но осталась одна нерешенная проблема — адреса страниц.
Все адреса в drupal по дефолту имеют вид node/[NID]. Многие оставляют это как есть, но не будет лишним сделать Человеко Понятные Урл.
Стандартный модуль path
Разработчики друпала прекрасно понимают что ЧПУ — необходимость подавляющего большинства сайтов, и не включить подобный функционал в систему, было бы глупо. Поэтому в базовой поставке системы идет модуль path, который как раз таки и добавляет возможность создания ЧПУ.
Чтобы понять как он работает, зайдите в любой материал, будь то новости или услуги, а затем перейдите в окно редактирования.
В самом низу окна редактирования есть вкладки, отвечающие за отображение материала. В этом списке нам нужна вкладка «Параметры адреса».

Справа вы увидите поле для настройки синонима. В нем как раз и можно задать то как будет выглядеть ссылка. Например укажем в поле «news/новость-про-ломтик-бекона»
![]()
И жмем «Сохранить». После чего наш материал становится доступным по адресу: site/news/новость-про-ломтик-бекона
Небольшое пояснение. Я сделал news по англ. потому что ранее мы создали представление (вьюху), при помощи которой мы реализовали страницу news со всеми новостями. И логичнее всего чтобы новости имели имели такой вид. Допустим можно просто в адресе удалить «новость-про-ломтик-бекона» и мы попадем на все новости. Также, при грамотно созданных хлебных крошках (breadcrumbs) это положительно повлияет на отображение сайта в гугле (не позиции а его отображение). Да и вообще, так правильно.
А после news я написал по-русски. Тем самым я показал что адреса могут содержать и русские буквы. Но данный пример не правильный, потому что нужно делать все в едином стиле, хотя это скорее всего мои убеждения. Если уж назвали news, то пусть название новости будет транслитом, или news будет по-русски. Как вам лучше, решайте сами, о том как это сделать речь пойдет дальше.
Автогенерация ЧПУ
Мы создали чпу только для одной новости. Конечно, учитывая что у нас не очень много страничек, можно пробежаться и сделать каждому материалу ЧПУ вручную. Но что делать если материалов больше 100? Это уже вызывает сложности, а что будет при 1000+? Как правило у них у всех один и тот же ЧПУ, а различаются он лишь заголовком. Поэтому нам необходимо автоматизировать данную работу. Для этого нам понадобится установить модуль pathauto (он зависит от модуля token — его тоже нужно установить).
После успешной установки и активации модуля, переходим в его настройки (/admin/config/search/path/patterns). В настройках все разделено на три категории: контент, таксономия и пользователи.
Рассмотрим раздел контента. Здесь мы можем настроить шаблоны ЧПУ для наших типов содержимых. Например, настроим для новости. Напишем «news/» а после этого поставим токен (некая переменная) из «постановочные шаблоны». Нам необходим токен [node:title], который выдает заголовок материала. В итоге получаем:

Теперь для всех новостей будет автоматически генерироваться ЧПУ формата news/название-материала.
Задайте для остальных типов содержимого форматы ЧПУ на свое усмотрение. Я сделал так:

Затем жмем «Сохранить настройки».
Вверху также есть дополнительные вкладки:
- Настройки — настройка генерируемых ЧПУ. Какие слова будут удаляться из ЧПУ, максимальная длина, символ замены пробела, регистр и т. д.
- Bulk update — обновление ЧПУ для всех указанных типов материалов, у которых нету ЧПУ.
- Delete alises — массовое удаление ЧПУ для всех материалов. Например. Если изменился формат ЧПУ, сначала удаляем, а потом генерируем новые.
Мы воспользуемся Bulk update, так как у нас задано всего лишь для одной новости. Для этого, разумеется, переходим на вкладку Bulk update и ставим все галочки, затем жмем «Обновить».
Все наши материалы теперь имеют ЧПУ и при добавлении новых материалов будут автоматически генерировать для себя синоним.
Транслитерация ЧПУ
Если вы делаете заголовок материала на русском, то и в ЧПУ будут русские слова. Что делать если необходимо чтобы в ЧПУ были только английские символы? Транслетировать при помощи модуля transliteration.
После установки и активации переходим на страницу настройки pathauto (/admin/config/search/path/settings) и устанавливаем галочку «Transliterate prior to creating alias».

Сохраняем настройки, удаляем текущие синонимы и генерируем новые.
P.s.
Возможно возник вопрос, почему в друпале ЧПУ называется синонимами? Если не возник, все равно прочитайте. При создании ЧПУ, старый адрес не пропадает и остается доступным.
Например, раньше одна из новостей имела адрес site/node/7, сейчас имеет адрес news/ham-swine-ground-round-brisket, но я также могу попасть на запись по старому адресу. Если Вас не устраивает такой расклад событий, можно установить модуль global redirect, который автоматически будет переадресовывать (!) на ЧПУ. Системный адрес вы никак не удалите, он никуда не денется.
Не стоит бояться и думать что это навредит SEO, ибо многие этим обеспокоены. Поисковые системы понимают что это коротки адрес статьи, а оригинальный тот что с ЧПУ. Это хорошо видно в исходном коде страницы.
![]()
Доработанная и исправленная статья о формировании красивых синонимов URL в Drupal. Рассматривается возможность совместного использования модулей Path, Pathauto и CCK.
В начале был Path.
Вероятно, вы уже знаете, что в Drupal встроен модуль Path (по умолчанию выключен), позволяющий создавать синонимы (то есть — псевдонимы или алиасы) для документов. После включения модуля при создании или редактировании документа становится доступным дополнительное поле «Настройки адресов». В этом поле можно указать альтернативный синоним URL для документа. То есть, если страница «Мои друзья» на вашем сайте имеет фактический адрес www.mysite.com/node/17, а вам нужно, чтобы адрес был вроде www.mysite.com/aboutme/myfriends, то всё, что следует сделать — просто указать синоним aboutme/myfriends в этом поле (именно так, то есть — всё, что ниже «корневого» слеша):
Drupal сохранит этот связанный синоним в базе, и все последующие ссылки на документ будут формироваться уже с учетом определенных для него синонимов. Также имеется возможность назначать синонимы для категорий (терминов таксономии), заменяя taxonomy/term/term_id на что-то более понятное человеку.
Всё это так, и написано об этом тоже уже много. Но мне этого недостаточно. Я искал возможность максимально автоматизировать формирование алиасов, вместе с тем сохранив определённую гибкость в их создании. Попробую объяснить, что же именно я хотел.
Задачи.
Итак, я бы хотел:
- Сделать формирование всех алиасов максимально прозрачным, с тем, чтобы ввод синонима URL или не требовался (пусть Drupal сделает это за меня) или же был предельно простым.
- Мне нравится, когда URL’ы включают в себя расширение «.html». Согласен, это мега-архаизм и излишество, но такая уж у меня слабость. В общем, я хочу, чтобы все сформированные Drupal’ом ссылки на моем сайте имели на своём конце старое доброе «.html».
- Заставить Drupal формировать синонимы URL, учитывающие принадлежность документа к определенной категории (т.е. термину таксономии) и соответственно наследующие синоним, ранее определённый мною для этой категории.
- Наконец, определить различные правила формирования синонимов для различных типов содержания.
- Например, я бы хотел, чтобы для блоговых нодов это было наподобие: blog/5.html, …, blog/25.html, …, blog/278.html, и т.д. и т.п. То есть URL должен включать в себя nid документа (или, возможно, дату).
- Для других же, статических типов содержания, мне нужна была возможность явно указать синоним непосредственно документа (например, «myarticle»), а на Drupal переложить все заботы, связанные с формированием и включением в URL синонима категории (или полного «пути») перед документом и любимого мною «.html» на конце. В итоге должно было получаться что-то вроде articles/all/myarticle.html.
Ну и что здесь такого, скажете вы. Модуль Pathauto решает все перечисленные задачи без шума и пыли. Да, решает. Почти все, за исключением последнего пункта. Но давайте по порядку.
Автопилот: Pathauto.
Модуль Pathauto действительно был создан для целей, связанных с автоматизацией формирования синонимов в Drupal. Включённый модуль «прозрачно» делает свою работу при каждом сохранении документа. Возможностей у него достаточно много. Основной функционал модуля построен на шаблонах преобразования синонима, определяемых пользователем для отдельных (или всех) типов содержания.
Шаблон представляет собой комбинацию из динамических компонентов или фрагментов статического текста. Доступные для включения в шаблоны компоненты перечислены в довольно объёмном списке, находящемся ниже этих полей. В качестве таковых, например, могут выступать: заголовок документа, дата и время его создания, название категории или словаря, синоним категории, название меню, к которому относится документ и ещё ряд других компонентов. Я не буду здесь приводить этот список, он действительно длинный, но всё же советую вам внимательно с ним ознакомиться
Кроме того, в Pathauto встроен механизм транслитерации заголовков документов для компонента [title]. При желании вы сможете автоматически получать URL’ы вроде «kak-ya-otdihal-s-druzyami-na-more», базирующиеся на тексте заголовка. Для корректной работы этого механизма с русским языком следует переименовать файл i18n-ascii.example.txt в папке модуля в i18n-ascii.txt.
Pathauto также предоставляет средства для автоматического формирования синонимов категорий и словарей, а также личных пользовательских папок. Но сейчас я не буду рассматривать эти возможности, поскольку мне они просто не нужны.
Итак, Pathauto допускает использование синонимов категорий ([catalias]) в качестве компонента шаблонов. Это хорошо, и значит, я смогу использовать эту особенность для формирования «пути» к документу, включающего в себя синоним термина таксономии, к которой относится материал. Также есть возможность сформировать URL’ы, комбинирующие синоним категории («путь») и дату создания документа, или его nid или ещё какой-либо компонент, и, наконец, моё любимое «.html» (!) в конце. На первый взгляд в нём есть всё то, что я хотел.
Однако, не всё. Если вы помните, я также хотел иметь возможность создавать свои синонимы для некоторых типов материалов. Но как «научить» Pathauto добавлять к автоматически формируемому «пути» мой синоним?
Здесь есть одна проблема, которая перечёркивает многие преимущества модуля, по крайней мере — в моём случае. Pathauto формирует всё, что от него требуется, но при этом обновляет все системные синонимы документа, привязывая вновь созданные модулем. И, к сожалению, модуль Pathauto не может использовать ранее назначенный синоним документа как компонент шаблона. Таким образом, все ваши попытки непосредственно указать синоним в поле «Настройка адресов» после первого же сохранения документа будут сведены на нет. А что делать, если, как я уже писал, я хочу сам назначать синонимы для документов определённого типа?
Выходит, что модуль Pathauto в чистом виде идеально подходит для автоматических машинно-правильных адресов. В моём случае это пригодилось бы при формировании URL’ов для блоговых нодов или других видов динамического содержания. Но для тех материалов, которые мне хотелось бы подавать как статические страницы, мне нужно нечто большее.
Гибкий рецепт: Path + Pathauto + CCK.
Каков же выход?
Выход в поиске способа предоставить модулю Pathauto информацию о предпочтительном URL документа. Эта информация должна быть сохранена вместе с документом, но отдельно от стандартного поля настройки адреса. Здесь мне поможет мощный инструмент для создания пользовательских полей в нодах Drupal’а — модуль CCK. Этот модуль позволяет добавлять различные виды полей к любым типам содержания и сохранять введенные в них данные в базе, как дополнительные данные для каждого нода. Это именно то, что мне нужно, поскольку CCK экспортирует имена полей в Pathauto в качестве возможных компонентов для шаблона преобразования.
- Итак, устанавливаю модуль CCK. Поскольку CCK является не отдельным модулем, а группой таковых (каждый из которых служит для создания и управления отдельным типом полей), то на странице управления модулями Drupal я включаю только два модуля из набора: Content и Text.
- После включения модуля на странице описания любого из имеющихся типов содержания появляется дополнительный пункт меню – «Fields».
- Для моих целей удобнее всего использовать тип содержания Page. Но я, пожалуй, создам новый тип содержания для своих статических страниц. Просто чтобы не было путаницы.
- Создаю новый тип документов, называю его, скажем – MyStaticPage и присваиваю ему машинное имя my_static_page. Затем открываю страницу добавления дополнительных полей CCK для этого типа.
- Добавляю новое поле типа Text, называю его, скажем: MyURL.
- В свойствах поля указываю – «Обязательно». Это значит, что поле должно быть обязательно заполнено пользователем (ведь мы же не хотим, чтобы Pathauto формировал «отсебятину» в случае пустого поля, верно?).
- Теперь при создании или изменении материалов типа MyStaticPage нам доступно специальное поле для ввода URL, в нём я и буду указывать мой синоним для документа.
- Перехожу к модулю Pathauto. В настройках «Node path settings» теперь появилось новое поле «Pattern for all MyStaticPage paths:». Вот здесь-то нам и нужно указать …что? Смотрим ниже список всех доступных компонентов. Вот оно: «[field_myurl]».
- Этот компонент использует информацию, сохранённую в нашем новом текстовом поле, его нам и нужно указать. Вводим шаблон: «[catalias]/[field_myurl].html».
- Для остальных, «нестатических», типов ставлю шаблон «[catalias]/[nid].html». То есть, это просто id документа внутри Drupal’а, мне так нравится. Можете поменять на дату, или на что-то другое.
- Поскольку теперь мне нужно обновить таблицу синонимов Drupal’а для имеющихся документов, я включаю опцию «Bulk update node paths» (можете пропустить, если у вас ещё нет документов), а также опцию «Create feed aliases» для формирования таких же синонимов в RSS фидере.
- Мне не нужно автоматическое формирование синонимов категорий (я предпочитаю их указывать сам), а потому во избежание путаницы я очищаю все поля в секции «Category path settings».
- Сохраняю настройки.
Теперь URL’ы всех новых страниц типа MyStaticPage будут автоматически формироваться Drupal’ом, комбинируя синонимы категорий, в которые они включены, и синонимы, определенные мною в поле MyURL при создании документа.
Последнее «но».
Осталось ещё одно «но». Модуль CCK при отображении документа с пользовательскими полями выводит также название поля и его содержание, что не есть хорошо. Они отображаются как в теле тезауруса, так и при просмотре документа.
Настройки модуля, к сожалению, не допускают возможности скрыть содержание поля при просмотре документа. Но выход всё-таки есть. Модуль CCK позволяет подключать собственные шаблоны для визуализации полей модуля, в которых при желании можно просто …ничего не выводить. Это позволит отключить отображение и названия поля и его данных. Для этого потребуется простейшая модификация файла template.php из вашей темы оформления. Эта процедура описана в файле readme.txt, находящемся в папке модуля CCK: modules/cck/theme/readme.txt, на основании этого файла я и опишу все последующие шаги.
Итак, находим в папке modules/cck/theme/ файл template.php. Как видите, он содержит единственную функцию phptemplate_field:
function phptemplate_field(&$node, &$field, &$items, $teaser, $page) {
$variables = array(
‘node’ => $node,
‘field’ => $field,
‘field_type’ => $field[‘type’],
‘field_name’ => $field[‘field_name’],
‘label’ => $field[‘widget’][‘label’],
‘items’ => $items,
‘teaser’ => $teaser,
‘page’ => $page,
);
}
Аккуратно копируем весь код функции и вставляем в конец файла template.php текущей темы оформления. Сохраняем файл. Добавленная функция переопределяет стандартную процедуру вывода полей CCK и «сообщает» модулю CCK, что забота о выводе полей теперь ложится на пользователя.
В соответствии с описанием, в папке текущей темы также нужно создать файл field-field_myurl.tpl.php (помните, что поле в моём примере выше называется field_myurl?). Этот файл — просто шаблон, в котором можно определить, как именно поле CCK будет отображаться в браузере, то есть, HTML-обвязку выводимых данных поля. Поскольку нам ничего не нужно выводить (мы хотим скрыть поле), то создаём пустой файл, а лучше — вообще ничего не создаём (ничего страшного не произойдёт). Для интереса можете посмотреть как может выглядеть шаблон вывода поля, открыв файл modules/cck/theme/field-field_body.tpl.php.
На этом настройка закончена. Помните о том, что, поскольку мы переопределили функцию вывода полей CCK, в будущем вам придётся создавать шаблоны вывода для всех новых полей CCK, иначе они отображаться не будут. Либо определить дополнительно общий шаблон для вывода полей CCK (field.tpl.php). Подробности — в файле modules/cck/theme/readme.txt.
Что же касается меня, то я совершил святотатство, надругавшись над своим модулем content.module из набора CCK, и вообще отключил вывод полей на уровне кода модуля. Я могу себе это позволить, поскольку поля CCK у меня пока больше нигде не используются. При необходимости я вернусь к способу скрытия полей CCK с помощью тем.
Что такое URL?
URL — это аббревиатура от «Uniform Resource Locator», который является
адресом страницы в сети. Это «имя», по которому браузер идентифицирует
отображаемую страницу. В примере «Посетите нас по адресу example.com«,
example.com — это URL-адрес главной страницы вашего веб-сайта. Пользователи
используют URL-адреса для нахождения информации в сети.
Что такое путь?
Путь — это уникальная, последняя часть URL для определенной функции или части
содержимого. Например, для страницы с полным URL http://example.com/node/7
путем является node/7.
Вот несколько примеров путей, которые вы можете встретить на вашем сайте:
- node/7
- taxonomy/term/6
- admin/content/comment
- user/login
- user/3
Что такое синоним?
Программное обеспечение ядра имеет функцию под названием «Синонимы URL»,
которая позволяет вам дать более понятное название содержимому. Итак, если у
вас есть страница «About Us» с путём node/7, вы можете настроить псевдоним
так, чтобы ваши посетители видели его как http://www.example.com/AboutUs.
Эту функциональность обеспечивает модуль ядра Path, который поддерживает
синонимы в URL.
Source file: content-paths.asciidoc
Содержание
Индексация прочих зон документа
Документы могут присутствовать в результатах выдачи поисковой системы без вхождения ряда слов из запроса в его текст и тексты входящих ссылок. Порой, в процесс поиска причин данного поведения SEO-специалисты наделяют значимыми качествами meta-тег Description, атрибут alt картинки и т.д., что некорректно для Яндекса. Приведем основные причины попадания документов в выдачу Яндекса, когда в тексте документа и входящих на него ссылках ЗАВЕДОМО отсутствуют слова из поискового запроса.
Прохождение кворума
Как известно, для попадания в выдачу по каждому запросу, документ должен набрать (пройти) определенный кворум.
Кворум — необходимая доля суммарного веса (IDF) слов из поискового запроса, которая должна присутствовать в тексте документа и/или текстах входящих на него ссылок для попадания в результаты поиска (SERP).
Как следует из определения, для попадания в результаты выдачи, документ должен содержать в себе и/или текстах входящих на него ссылок все или заданную минимальную долю веса слов из запроса. Доля высчитывается как функция от длины запроса (в словах) и весов слов входящих в него по формуле представленной ниже (Рис.1), где:
- Q — поисковый запрос
- q (i) — i-ое слово запроса
- w (q(i)) — функция веса слова
- D — обрабатываемый документ
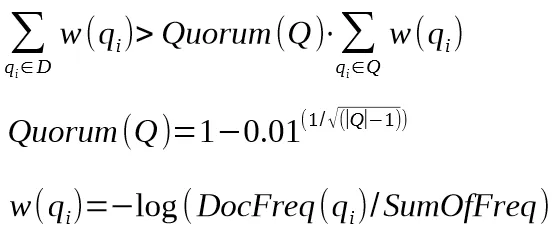
Рис. 1. Формула для кворума (доли веса) из презентации одного из разработчиков Яндекса — Дениса Расковалова. Формула известна и сильно ранее, в частности встречается и в статье разработчиков 2004 года.
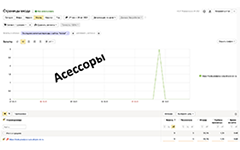
Численный параметр 0.01 из формулы носит название мягкости и может меняться в зависимости от настроек поисковой системы. Имеются определенные основания полагать, что значение мягкости в Яндексе может быть отлично от 0.01 и принимать значение 0.06. Для двух данных значений была вычисленная минимальная доля веса (кворум), которая должна быть найдена для документа для включения в результаты выдачи (Рис. 2).
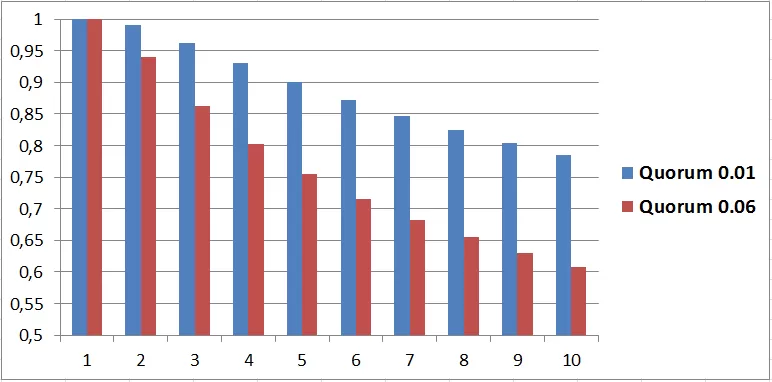
Рис. 2. Вычисленное значение Quorum для двух значений мягкости — 0.01 (синие столбцы) и 0.06 (красные столбцы) в зависимости от длины запроса в словах. По оси Y — минимальная доля суммарного веса для прохождения кворума, по X — число слов в запросе от 1 до 10.
Как видно из гистограммы, для включения в ранжирование документа по пятисловному поисковому запросу (при коэффициенте мягкости 0.06) достаточно чтобы в нём встречалось 4 слова из запроса (при равенстве весов всех слов из запроса). Более того, правила прохождения кворума могут меняться в зависимости от запроса и числа найденных по нему документов.
Таким образом, мы приходим к первому возможному случаю, когда в тексте документа и/или текста входящих на него ссылок встречаются не все слова из запроса, а только часть, но этой части оказывается достаточно для прохождения кворума. Пример представлен ниже (Рис. 3):
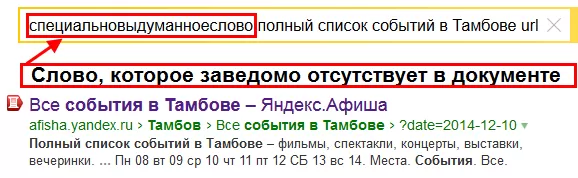
Рис. 3. Демонстрация прохождения документа по кворуму в Яндексе со словом, которое заведомо отсутствует в его тексте и анкорах ссылок.
Синонимы слов из запроса
Второй распространенный случай присутствия документа в SERP без прямого вхождения слов из поискового запроса — это вхождение СИНОНИМОВ ЗАПРОСА в текст и анкоры входящих на него ссылок.
Кроме того, не все синонимы подсвечиваются в сниппете, что может вводить SEO-специалистов в заблуждение. Определить, что документ найден в Яндексе с помощью синонимов можно используя GET-параметр «nosyn». На иллюстрациях ниже (Рис. 4 и Рис. 5) представлен как раз такой пример, когда при обработке поискового запроса [мебель офис] в переколдовку добавляется слово «офисная», в результате чего документы с вхождением таких фраз как «офисная мебель» оказывается найденными. При добавлении GET-параметра «nosyn» — документ пропадает из выдачи (Рис. 5).

Рис. 4. Демонстрация попадания документа в выдачу Яндекса за счёт синонимов.
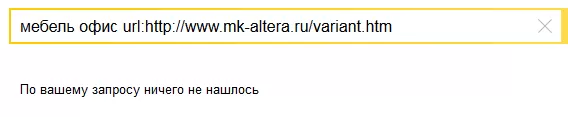
Рис. 5. Использование GET-параметра «nosyn» для проверки того, что документ найден с помощью синонимов.
Важно отметить, что корректно говорить о синонимах ЗАПРОСА, а не о синонимах СЛОВ из него, так как в зависимости от точной формулировки запроса одно и то же слово может, как является синонимом, так и не быть таковым.
К данному же случаю стоит отнести и прочие примеры, когда документ оказывается найден из-за механизма переколдовки поискового запроса (к словам из запроса, в зависимости от его содержимого, добавляются: синонимы, аббревиатуры, перевод и т.д.)
Вхождение в URL
Третий, весьма распространенный случай попадания в выдачу без вхождения слов из запроса, это вхождение всех или некоторых слов в виде транслита в URL-документа.
Интересным здесь также оказывается то, что не все виды транслита, которые понимает поисковая система, подсвечиваются. Ниже (Рис. 6) представлен аналогичный пример, когда документ оказывается релевантным запросу [шуба] за счёт вхождения в URL конструкции вида «wuba».
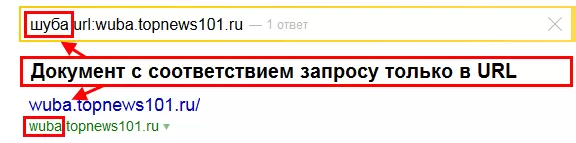
Рис. 6. Ранжирование документа за счёт вхождения в URL запроса без подсветки самого транслита в адресе.
Стоит отметить, что вхождение транслита слов из запроса в URL повышает вероятность документа набрать кворум в Яндексе.
Запросный индекс
Известно, что поисковая система Яндекс фиксирует совокупность поисковых запросов, по которым осуществлялись заходы на заданный документ. Данная совокупность запросов носит название запросного индекса и презентация с конференции AllInTopConf. Существует точка зрения, что документ может быть найден и фигурировать в выдаче только за счёт запросного индекса. Текущие проверки не позволяют безоговорочно поддержать её, но наблюдения за данным аспектом продолжаются.
Индексация прочих зон документа
Поисковые системы включают в текстовый индекс содержимое не всех зон документа. В частности, известно, что Яндекс не осуществляет поиск по таким зонам как: мета-теги Description, Keywords, атрибуты alt и title картинок и ряду других. Но, данные утверждения могут перестать быть корректными с течением времени. Требуется проводить регулярные наблюдения за выдачей и индексатором. В частности, на текущий момент имеется возможность производить поиск по некоторым служебным зонам.
Разбор примера
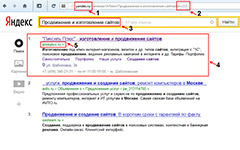
Иногда, аспекты описанные выше не принимаются во внимание и SEO-специалисты могут делать ошибочные выводы. В частности по запросу [безопасные коляски трансформеры] находится документ, в сниппете которого фигурирует текст из meta-тега Description (Рис. 7). Слово «безопасные» же отсутствует в тексте документа и входящих на него ссылках. Может Description начал давать плюс? Нет, на самом деле, здесь срабатывает мягкость и документ проходит кворум без этого слова. Данное утверждение можно проверить заменив слово «безопасные» на произвольное, скажем «вурбалакийсын» (Рис. 8).

Рис. 7. Документ с вхождением в сниппет слова «безопасные».
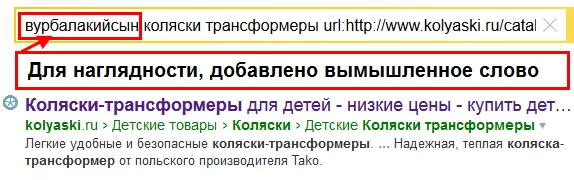
Рис. 8. Ранжирование документа за счёт срабатывания мягкости.
Также, убедиться к отсутствии текста из meta-тега Description в текстовом индексе можно задав фразу из Description в кавычках (Рис. 9).
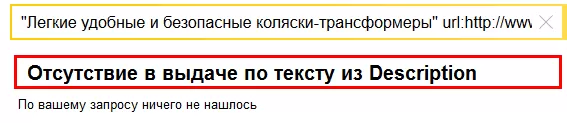
Рис. 9. Отсутствие заданного документа в выдаче по тексту точно составленному из Description.
Надеемся, что рассмотренные выше примеры помогут SEO-специалистам производить аналитику выдачи и успешно продвигать сайты самостоятельно.

Подписывайтесь
на рассылку
Понравилась статья?
— по оценке 8 пользователей
15 марта, 21:22
-

Что такое SEO?
Простыми словами о поисковом продвижении сайтов.22 ноября
-

Как продвигать свои товары на …
Какие карточки товара «любит» Озон, по каким принципам их ранжирует, как получить трафик и увеличить продажи на этой площадке?1 апреля
-

9 способов продвижения товаров…
В 2021 и 2022 году популярность маркетплейсов продолжает расти, что говорит о большом потенциале этого направления для бизнеса.28 февраля
-
-

-
-

-
-

-
-
-
Что такое лид-магнит?
Как с помощью этого инструмента можно уменьшить CPA и кратно повышаем конверсию привлекаемого трафика.30 апреля









‹
›
-

Баден-Баден от Яндекса
Как работает новый алгоритм Баден-Баден от Яндекса? Диагностика фильтров (запросозависимый, хостовый). Определение переоптимизированных тексто…17 апреля
-
Два текстовых фильтра Яндекса
Статья изначально существовала как инструкция для внутреннего использования внутри сотрудников интернет-агентства «Пиксель Плюс».12 апреля


Опубликовано Elena Ivleva
— чт, 01/07/2021 — 21:13
При создании структуры сайта на Drupal 9 мне регулярно встречаются очень схожие задачи. Например, создать с помощью модулей Pathauto и Token синоним пути для материала, который включал бы термин таксономии из поля Term reference.
Для самих терминов как правило нужно создать синононим, включающий всю иерархию. то есть родителей, разделенных слешем, если они есть.
Вот наиболее распространенные примеры токенов:
Иерархические синонимы терминов таксономии.
[term:parents:join-path]/[term:name]Иерархический синоним для материала, если у материала может быть выбран только один термин из словаря и термин может иметь иерархию.
Здесь field_stile_collezione поле Term reference с единственным возможным значением, причем в поле может быть выбран термин верхнего уровня, а может быть термин, имеющий родителей.
[node:field_stile_collezione:entity:parents:join-path]/[node:field_stile_collezione]/[node:title]Возможные результаты:
classico/eleonora
classico/eleonora/composizione
Другая ситуация, как на данном сайте, когда в поле Term reference может быть выбрано несколько значений, причем из разных уровней. У меня еще в каждом материале есть несколько полей Term reference, каждое поле для своего словаря. тогда вариант со строгой иерархией мне не подходит и я использую для материалов другой синоним.
[node:field_spravochnik]/[node:field_resurs]/[node:title]В результате все термины из одного поля записываются через дефис.
Поисковая система Google является самой популярной в мире. И неспроста. Разработчики стремятся сделать поиск нужной информации максимально комфортным, используя для этого различные инструменты.
Одним из таких инструментов является язык поисковых запросов Google – это набор специальных операторов, позволяющих сделать запрос более точным и конкретизированным.
Приведем простой пример. Допустим, нас интересует история Советского Союза с 1930-х по 1960-е года. Если ввести в поисковую строку «история СССР», в результатах будут показаны сайты с историей за все время. Если добавить «история СССР с 1930-го по 1960-й», поисковик будет искать совпадения именно по этим двум числам.
Но нас интересует не только 1930-й и 1960-й года, но и все, что между ними. Применив оператор «..» (две точки), мы дадим «Гуглу» понять, что нас интересует весь период истории с такого-то и по такой-то год. То есть поисковик будет искать все даты в диапазоне с 30-го по 60-й (они даже будут выделены в сниппетах).
Интервал поиска в Google (две точки)
")
Интервал поиска в выдаче Google
Таким образом, данный оператор помог и пользователю, избавив его от лишних ссылок в выдаче, и поисковой системе, уточнив запрос.
Таких операторов у Google много. И далее мы поговорим о каждом из них более подробно.
Виды операторов
Сам Google не особо сильно афиширует информацию о своих «помощниках». На официальном сайте поддержки поисковика есть информация лишь о некоторых операторах, но далеко не обо всех.
В данной статье будет описан весь язык запросов, начиная с самых популярных и известных и заканчивая «скрытыми», о которых «Гугл» почему-то умалчивает.
Условно все операторы можно поделить на две группы:
- Простые – представлены, как правило, в виде одного-двух спецсимволов, знаков препинания.
- Сложные (документные) – целые слова (фразы) или предлоги.
К простым относятся:
- + (плюс);
- — (минус);
- .. (две точки);
- “ ”(кавычки);
- ~ (символ тильда);
- * (звездочка);
- @ (символ at);
- # (решетка);
- $ (знак доллара).
К сложным (документным) относятся:
- AND,
- site,
- related,
- cache,
- filetype,
- info,
- link,
- allintitle,
- intitle,
- allinurl,
- inurl,
- allintext,
- intext,
- allinanchor,
- inanchor,
- define,
- movie.
Как видите, операторов в языке запросов Google много. На сайте поддержки поисковика их всего 10. Да и описаны они там без каких-либо конкретных примеров. Почему так мало? Одним лишь разработчикам известно. Возможно, некоторые из них не особо популярны и мало где применяются, потому «Гугл» и решил их не упоминать.
Чтобы компенсировать нехватку данных, мы опишем весь синтаксис более подробно.
+ (плюс)
Данный оператор позволяет учесть то или иное слово (предлог) в обязательном порядке. Для этого нужно добавить перед ним +. В результате, поисковая система покажет только те ресурсы, где отмеченное слово (предлог) содержится. В одном запросе может быть сразу несколько таких плюсов.
Например:
- Достоевский идиот содержание +кратко;
- продвижение сайта +под +ключ.
Ключевое слово в обязательном порядке (плюс)
")
Ключевое слово в обязательном порядке в поиске
— (минус)
Если плюс позволял находить сайты, которые обязательно содержат, то минус ищет ресурсы, которые обязательно НЕ содержат указанное слово (исключает его).
Он также добавляется впереди слова и может употребляться несколько раз в одном запросе.
Примеры:
- Создание сайта –самостоятельно;
- рецепт суши -филадельфия –хосомаки.
.. (две точки)
Этот оператор мы уже упоминали в самом начале статьи. Он позволяет искать информацию в определенном числовом диапазоне. Это могут быть даты, цены, измерения и т. д. Все числа из диапазона будут подсвечиваться в сниппетах.
Давайте приведем еще парочку примеров:
- купить игровой ноутбук $200..$300;
- женская одежда reebok 40..45 размеры купить.
| (прямая черта)
Чтобы «Гугл» искал совпадения по любому из ключевых слов, содержащихся в запросе, их необходимо связать символом «|» (или).
Вместо прямой черты можно использовать предлог «OR» (обязательно заглавные) – результат идентичен.
Примеры:
- женское платье розовое | нежно-розовое | светло-красное | малиновое;
- купить флешку 32гб OR 64гб OR 128гб.
Оператор OR (или)
")
Оператор OR в Google
“ “ (кавычки)
Применяются в случаях, когда необходимо точное совпадение словоформы, фразы. Система исключает сайты с иными формами написания, иным порядком слов и т. д.
Данный оператор хорошо сочетается с другими, позволяя делать запрос максимально конкретизированным (например, с минусом).
Примеры:
- ”емкость батареи Samsung S8”;
- купить iphone 8 -«iphone 8 plus» -«iphone 8s».
Исключение из поиска Google конкретных значений слов (кавычки)
")
Исключение из поиска конкретных значений (кавычки)
~ (тильда)
Чтобы помимо указанного ключевого слова поисковик искал и его синонимы, необходимо впереди добавить символ «тильда»:
Например:
- ~стагфляция причины,
- как использовать корень ~репейника.
Оператор ‘тильда’ в Google — поиск синонимов

Оператор ‘тильда’ в Google
* (звездочка)
Символ «*» позволяет искать пропущенные слова из устоявшихся и популярных фраз, выражений, строк музыкальных и художественных произведений, цитат. Помогает, когда пользователь забыл или не может четко сформулировать свой запрос.
Например:
- первый закон термодинамики для*процесса;
- вот где*зарыта.
Оператор ‘звездочка’ в Google — пропущенные слова

Оператор ‘звездочка’ в Google
@ (символ at)
Оператор «at» (или, как его в простонародье называют, собака) служит для поиска информации по тегам в социальных сетях.
Примеры:
- @lordjurrd,
# (решетка)
В языке поисковых запросов Google есть еще один оператор для поиска информации по тегам – решетка. Только в данном случае поиск осуществляется именно по хештегам и не только в социальных сетях.
Все сайты с указанным хештегом отобразятся в результатах выдачи.
Примеры:
- как прошли #выборы2018;
- #деньвсехвлюбленных.
$ (знак доллара)
Чаще всего употребляется в коммерческих запросах для того, чтобы найти товар или услугу по конкретной цене или в конкретном ценовом диапазоне, если применить оператор «..».
Добавив символ «$» перед числом, пользователь заставит поисковую систему искать совпадения именно в ценах (не только в долларах, но и в любой другой валюте). В результатах выдачи совпадения будут подсвечены.
Например:
- купить телевизор LG $300,
- фотоаппарат $200..$400.
Оператор ‘знак доллара’ в Google — поиск конкретной цены

Оператор ‘знак доллара’ в Google
AND
Данный оператор аналогичен обычному пробелу – позволяет учитывать все ключевые слова, расположенные слева и справа от него (прописывать только заглавными).
Использовать его не обязательно, но стоит привести пару примеров:
- детские AND футбольные AND бутсы;
- барселона AND реал AND эль AND класико.
site
Если в поисковой строке написать «site:», а после указать домен ресурса, то поиск будет осуществлен только внутри указанного сайта.
Особо часто применяется для поиска информации на крупных площадках и порталах, где поиск вручную не настолько эффективен.
Например:
- site:ru.wikipedia.org что такое математический анализ;
- site:rookee.ru продвижение смарт-ссылками.
Оператор ‘site’ в Google — поиск внутри сайта

Оператор ‘site’ в Google
related
Оператор «related:» позволяет искать информацию на площадках со схожей тематикой указанного ресурса. Употребляется, когда пользователь хочет найти аналогичный контент на других сайтах.
Так же, как и с предыдущим «помощником», после двоеточия необходимо указать домен исходной площадки.
Чтобы поисковик нашел не просто сайты-аналоги, а конкретную информацию на их страницах, после домена необходимо задать свой запрос.
Примеры:
- related:aliexpress.com;
- related:amazom.com ноутбуки Lenovo.
cache
Поисковая система Google при индексации страниц сохраняет их в кеше у себя на серверах. Если по каким-то причинам сайт перестал работать (например, по техническим), можно найти их кешированные версии при помощи оператора «cache:», указав URL-адрес искомой веб-страницы.
Также можно добавить ключевые слова для поиска определенной информации на указанной странице.
Примеры:
- cache:https://www.youtube.com/watch?v=5tvGJsen9mo;
- cahce:https://auto.ru bmw m6.
filetype
Чтобы найти не просто html веб-страницу, а документ в конкретном формате (pdf, doc, rtf и т. д.), необходимо добавить к запросу «filetype:» и указать нужный формат.
То есть мы указываем поисковику, документы какого формата нужно искать.
Например:
- форма 16 filetype:pdf;
- влияние выхлопных газов на организм человека filetype:doc.
Оператор ‘filetype’ в Google — поиск в конкретном формате

Оператор ‘filetype’ в Google
info
Оператор «info:» представляет большую ценность для веб-мастеров, так как позволяет получить различную информацию об указанном веб-адресе.
Пример использования:
- info:vk.com;
- info:rookee.ru.
link
Позволяет получить список сайтов-доноров, ссылающихся на указанный домен. Также используется веб-мастерами для поиска полезной информации (в том числе и о конкурентских ресурсах).
Например:
- link:https://destacar.de;
- link:http://www.consultant.ru.
allintitle (intitle)
«allintitle:» используется для поиска страниц, содержащих заданную фразу в тайтле (в заголовке). Учитываются все слова, введенные после двоеточия.
«intitle:» – аналогично, но учитывается только одно слово, стоящее сразу после оператора (остальные ключи будут содержаться не обязательно в заголовке).
Примеры:
- allintitle: демонтаж деревянных окон;
- allintitle: как составить брачный договор;
- раскрутка вконтакте под intitle:ключ;
- intitle:рубль прогноз на 2020 год.
Оператор ‘allintitle (intitle)’ в Google — поиск по title страниц
' в Google - поиск по title страниц")
Оператор ‘allintitle (intitle)’ в Google
allinurl (inurl)
Если использовать его, поисковик «Гугл» будет искать совпадения в URL-адресе:
«allinurl:» учитывает все слова после двоеточия;
«inurl:» учитывает только первое.
Примеры:
- allinurl: продвижение группы ВК;
- allinurl: recept tom-yan;
Оператор ‘allinurl (inurl)’ в Google — поиск по URL
' в Google - поиск по URL")
Оператор ‘allinurl (inurl)’ в Google
- inurl:w222 стоимость в москве;
- inurl:tom-yan рецепт.
Оператор ‘allinurl (inurl)’ в Google — поиск по URL
' в Google - поиск по URL")
Оператор ‘allinurl (inurl)’ в Google
allintext (intext)
Данный оператор работает по тому же принципу, что и два предыдущих. Изменяется лишь место для поиска совпадений.
«allintext:» и «intext:» ищут заданные ключи непосредственно в тексте на страницах (в контенте), учитывая все или только первое слово соответственно.
Примеры использования:
- allintext: остеология это наука;
- allintext: три принципа избирательного права в РФ;
- таргетированная реклама ВК intext:реальные отзывы;
- intext:би-2 все музыкальные альбомы группы.
allinanchor (inanchor)
Последние операторы из категории allin (in) в языке поисковых запросов Google. В данном случае совпадения ищутся в анкоре.
Анкор – это текст гиперссылки (то, что видит пользователь). Так как в анкор можно поместить любой текст, в него зачастую добавляют ключевые слова веб-страницы, на которую ведет ссылка. И именно по этим ключам будет осуществляться поиск, если в запрос добавить «allinanchor» или «inanchor».
Например:
- allinanchor: купить авиабилеты онлайн;
- купить видеокарту inanchor:gtx1060;
- inanchor: лечение хронического бронхита.
Оператор ‘allinanchor (inanchor)’ в Google — поиск по анкору
' в Google - поиск по анкору")
Оператор ‘allinanchor (inanchor)’ в Google
define
Один из самых полезных «помощников» в поиске информации для тех, кто часто имеет дело с терминологией.
«define:» дает команду поисковой системе искать именно определения (страницы, на которых есть определение). В большинстве случаев Google сам даст пояснение в отдельном окне в самом начале выдачи.
Например:
- define: бюджетная ссуда;
- define: партизанский маркетинг.
Оператор ‘define’ в Google — искать определение

Оператор ‘define’ в Google
movie
Применяется, если необходимо найти информацию именно по фильмам. Названия некоторых фильмов состоят из одного-двух слов, которые употребляются и в обиходе. Получая такой запрос, Google не понимает, что именно пользователь хочет найти: определение, тематическую статью, фильм или что-то еще. Оператор «movie» уточняет намерение пользователя.
Примеры:
- movie: любовь;
- movie: пианист.
Оператор ‘movie’ в Google — поиск по фильмам

Оператор ‘movie’ в Google
Как видите, операторов в языке запросов Google много. Запоминать их все вовсе не обязательно. Достаточно выучить наиболее полезные и часто используемые в своей практике. А если что-то забыли – всегда рады видеть вас снова на страницах нашего сайта.
Возможно, на момент прочтения статьи некоторые из операторов уже не будут работать (в силу появления новых технологий). Ведь «Гугл» никогда не стоит на месте и постоянно обновляет свои технологии. Он стремится по максимуму облегчить процесс поиска информации, и такие «помощники» лишнее тому подтверждение.