Using synonyms is undoubtedly one of the most important techniques in a search engineer’s tool belt. While novices sometimes underestimated their importance, almost no real-life search system can work without them. At the same time, some complexities and subtleties arising from their use are sometimes underestimated, even by advanced users. Synonym filters are part of the analysis process that converts input text into searchable terms, and while they are relatively easy to get started with, their use can be quite varied and require some deeper understanding of concepts before applying them successfully in a real-world scenario.
There have been some recent improvements around analysis in Elasticsearch lately. The most notable is probably functionality that allows for reloading search-time analyzers, which in turn enables search-time synonyms to be changed and reloaded. In addition to presenting this new API, this blog will answer some common questions around using synonyms and point out some frequent caveats around their use.
Why use synonyms?
To understand the usefulness and flexibility of synonyms, let’s take a quick look at how most of today’s search engines work internally. Documents and queries are analyzed and reduced to their smallest units, often called tokens, which are essentially abstract symbols. The matching process when searching uses simple string similarity, which is the reason why even small spelling mistakes (“hous”) or the use of a plural of a word (“houses”) in a query won’t match a document containing only the singular (“house”). Things like stemmers or fuzzy queries address some of the most common of these problems, but they don’t bridge the gap between relating concepts and ideas or between slightly different vocabulary usage in the documents and queries.
This is where synonyms shine. The Greek origins of the word are the prefix σύν (syn, “together”) and ὄνομα (ónoma, “name”). The origin of the term already shows that synonyms describe different words with exactly or nearly the same meaning in the same language or domain. In practice, this can range over general synonyms (“tired” vs. “sleepy”), abbreviations (“lb.” vs. “pound”), different spelling variations of products in ecommerce search (“iPod” vs. “i-Pod”), small language differences (like British English “lift” vs. American English “elevator”), expert vs. layperson language (“canine” vs. “dog”), or simply denoting the same concept in two ways (“universe” or “cosmos”). By providing appropriate synonyms rules, the search engineer can provide information about which words in their domain mean similar things and should thus be treated similarly.
For a search engine it is important to know which terms in documents and queries should match, even though they look different. Since this is highly domain specific, users need to provide the appropriate rules. Synonyms filters, which can be used in custom analyzers, replace or add additional tokens based on user-defined rules, either at index time in order to store, for example, both variations of a word in an indexed document, or at query time in order to expand the query terms and to match more relevant documents. We’ll discuss some advantages and disadvantages of these two approaches a bit later on.
When to be mindful about using synonyms
Synonym filters are a very flexible tool, which leads people to overuse them in certain situations. For example, they’re sometimes used as a brute-force replacement of stemmers, with large synonyms files containing grammatical variations of verbs and nouns. While this approach is possible, performance is usually worse and maintenance is harder than when using real stemmers or lemmatizers. The same goes for correcting spelling errors. If there are only a handful of very common spelling mistakes, such as in an ecommerce setting, trying to correct these using synonyms is sometimes advisable. But if the problem is more general, then using fuzzy queries or using character ngram techniques are more sustainable approaches. Also consider the alternatives to synonym expansion in the analysis chain. Sometimes enhancing documents in an ingest pipeline or some other client-side process is more flexible and manageable than using synonyms in the more restricted analysis process. For example, you could detect named entities in your documents using common named entity recognition (NER) frameworks and encode them in unique identifiers in your pre-processing pipeline or at ingest time. If you then apply the same process to your user’s queries before sending them to Elasticsearch, you get the same effect but usually gain more control.
Also, it is tempting to use synonyms for other notions of “sameness,” like grouping certain species of animals under a common term, or even building taxonomy support for your domain. This is where things get really interesting and there is much to explore, but keep in mind synonyms are not always the best choice and can lead to your system behaving in unexpected ways if not used carefully.
Index- vs. search-time synonyms
Synonyms are used in analyzers that can be used at index time or at search time. One of the most frequent questions around the use of synonym filters in Elasticsearch is, «should I use them at index time, search time, or both?» Let’s look at applying synonym filtering at index time first. This means terms in indexed documents are replaced or expanded once and for all, and the result is persisted in the search index.
Index-time synonyms have several disadvantages:
- The index might get bigger, because all synonyms must be indexed.
- Search scoring, which relies on term statistics, might suffer because synonyms are also counted, and the statistics for less common words become skewed.
- Synonym rules can’t be changed for existing documents without reindexing.
The last two, especially, are a great disadvantage. The only potential advantage of index-time synonyms is performance, since you pay the cost for the expansion process upfront and don’t have to perform it each time again at query time, potentially resulting in more terms that need to get matched. This, however, usually isn’t a real issue in practice.
Using synonyms in search-time analyzers on the other hand doesn’t have many of the above mentioned problems:
- The index size is unaffected.
- The term statistics in the corpus stay the same.
- Changes in the synonym rules don’t require reindexing of documents.
These advantages usually outweigh the only disadvantage of having to perform the synonym expansion each time at query time and potentially having more terms to match. On top of that, search-time synonym expansion allows for using the more sophisticated synonym_graph token filter, which can handle multi-word synonyms correctly and is designed to be used as part of a search analyzer only.
In general, the advantages of using synonyms at search time usually outweigh any slight performance gain you might get when using them at index time.
However, there used to be another caveat when using search-time synonyms. Although changing the synonym rules doesn’t require reindexing the documents, in order to change them you had to close and reopen the index temporarily. This was necessary because analyzers are instantiated at index creation time, when a node is restarted, or when a closed index is reopened. In order to make changes to a synonym rule file visible to the index, one had to first update the file on all nodes, then close and reopen the index. But this is no longer the case.
Synonyms, reloaded
Starting with Elasticsearch 7.3, this reopening of indices in order to see changes in synonym files is no longer needed. We added a new endpoint that makes it possible to trigger reloading of analyzer resources on demand. Calling this new endpoint will reload all analyzers of an index that have components in them that are marked as updateable. This, in turn, makes those components only usable at search time.
For synonym filters, marking them as updateable and calling the reload API makes changes to the synonyms configuration file on each node visible to the analysis process. Updating synonym rules that are part of the filter definition (via the synonyms parameter) isn’t possible, but those should be mostly used for ad-hoc testing purposes. In any case, configuring synonyms using a configuration file has several advantages:
- They are easier to manage! In a production system, there can be many synonym rules, and since those affect search relevance a lot, they should be treated as an integral part of the configuration that needs to be version controlled and tested with any update.
- Synonyms are often derived from other sources or created by an algorithm running on your data. Reading from files skips the need to put them into the filter configuration.
- The same synonym file can be used in different filters.
- Larger synonym rule sets take up much memory in the Elasticsearch cluster state that stores meta information about index settings. In order to not increase cluster size unnecessarily, it is advisable to store larger synonym rule sets in configuration files.
For demonstration purposes, let’s assume you put an initial my_synonyms.txt file containing the following single rule into the config directory of your Elasticsearch nodes. Let’s assume the file initially only contains the following rule:
universe, cosmos
Next, we need to define an analyzer that references this file in a synonym filter:
PUT /synonym_test
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"synonym_analyzer": {
"tokenizer": "whitespace",
"filter": ["my_synonyms"]
}
},
"filter": {
"my_synonyms": {
"type": "synonym",
"synonyms_path": "my_synonyms.txt",
"updateable": true
}
}
}
}
}
}
Note that we marked the synonym filter as updateable. This is important, because only updateable filters are reloaded when we call the new reloading endpoint, but this also has the side effect that analyzers that contain updateable filters are no longer allowed to be used at index time. But let’s check first that synonyms are applied correctly by running a quick test through the _analyze endpoint:
GET /synonym_test/_analyze
{
"analyzer": "synonym_analyzer",
"text": "cosmos"
}
This should return two tokens, one also being “universe,” as expected. Let’s add another rule to the synonyms.txt file by adding a second line:
lift, elevator
This is the point where previously you had to close and reopen the index again for these changes to show up. Now you can simply call the new endpoint:
POST /synonym_test/_reload_search_analyzers
The request doesn’t require a body but can be restricted to one or more indices using the typical index wildcard patterns. The response includes information about which analyzers have been reloaded and which nodes have been affected:
{
[...],
"reload_details": [{
"index": "synonym_test",
"reloaded_analyzers": ["synonym_analyzer"],
"reloaded_node_ids": ["FXbmbgG_SsOrNRssrYcPow"]
}]
}
Running the above _analyze request on the term “lift” now also returns “elevator” as a second synonym token.
A few things to note though. As mentioned above, a filter that is marked as updateable should be used at search time, so the correct way of using the synonym analyzer we defined above on a field would be:
POST /synonym_test/_mapping
{
"properties": {
"text_field": {
"type": "text",
"analyzer": "standard",
"search_analyzer": "synonym_analyzer"
}
}
}
Also, reloading works only for synonyms that are loaded from files — changing the synonyms defined via settings in a filter is not supported. Lastly, in practice you need to make sure to apply updates to synonym files across all nodes of your cluster. If the analyzer on some nodes sees different versions of the file, you might get differing search results depending on which node is used in a search. If this happens in relation to a synonym, the first thing to check is that your synonym files are the same on each node and then retrigger the reload.
In summary, the new _reload_search_analyzer endpoint allows you to quickly revise and change query-time synonyms without the need to reopen your indices. For example, by examining your query logs you can determine if users search by different terms than exist in the indexed documents and apply those additions on the fly. Adding synonyms can have unexpected side effects on relevance scoring though, so it is advisable to perform some sort of testing (be it A/B testing or something like the ranking evaluation API) first before directly applying changes in production.
Being a part of the (analysis) chain gang
Another frequently asked question around synonym filters is their behavior in more complex analysis chains. In most scenarios you will put some common character or token filters in front of your synonym filter, such as a lowercase filter. This means all tokens passing the analysis chain will be lowercased before applying the synonym filter. Does this mean the input synonyms in your synonym rules need to be lowercased as well in order to match? Let’s try this simple example:
PUT /test_index
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"synonym_analyzer": {
"tokenizer": "whitespace",
"filter": ["lowercase", "my_synonyms"]
}
},
"filter": {
"my_synonyms": {
"type": "synonym",
"synonyms": ["Eins, Uno, One", "Cosmos => Universe"]
}
}
}
}
}
}
GET /test_index/_analyze
{
"analyzer": "synonym_analyzer",
"text": "one"
}
You can verify that the lowercase input text gets expanded to three tokens in the above example, which shows that the lowercasing is also applied to the synonym filter rules. Also the right-hand side of replace rules like the “Cosmos => Universe” rule above is rewritten as you can see by the lowercase output of:
GET /test_index/_analyze
{
"analyzer": "synonym_analyzer",
"text": "cosmos"
}
In general, synonym filters rewrite their inputs to the tokenizer and filters used in the preceding analysis chain. However, there are some notable exceptions to this: Several filters that output stacked tokens (such as common_grams or the phonetic filter) are not allowed to precede synonym filters and will throw errors if you try to do so. Others, like the word compound filters or synonym filters themselves are skipped when they precede another synonym filter in the chain. The latter rule is important to make chaining of synonym filters possible. We will see this in action in the following example.
So what happens if you put two or more synonym filters in a row? Will the output of the former be the input of the latter, making chaining of synonym filters somewhat of a transitive operation? Let’s try the following example:
PUT /synonym_chaining
{
"settings": {
"index": {
"analysis": {
"filter": {
"first_synonyms": {
"type": "synonym",
"synonyms": ["a => b", "e => f"]
},
"second_synonyms": {
"type": "synonym",
"synonyms": ["b => c", "d => e"]
}
},
"analyzer": {
"synonym_analyzer": {
"filter": [
"first_synonyms",
"second_synonyms"
],
"tokenizer": "whitespace"
}
}
}
}
}
}
GET /synonym_chaining/_analyze
{
"analyzer": "synonym_analyzer",
"text": "a"
}
The output token would be “c”, which shows that both filters are applied in consecutive order, with the first filter replacing “a” with “b”, and the second replacing this input with “c”. If instead you try “d” as input, it gets replaced with “e” (the first rule doesn’t get applied) but if you use “e” instead, the token gets replaced with “f” in the first filter, leaving the second filter nothing to match on.
Remember that we just talked about the exceptions to rewriting against preceding token filters? If the second_synonyms filter in the example above would have applied the rules of the first filter to its rule set, it would have changed its own d => e rule to d => f (because the preceding filter’s e => f rule would have been applied). This behavior used to be a source of confusion in earlier versions of Elasticsearch, and is the reason why synonym filters are now skipped when processing the synonym rules of following filter. It will work as described in version 6.6 and later.
Back to the future
In this short blog, we just scratched the surface of what you can accomplish using synonyms and tried to answer some frequent questions around their usage. Synonyms are a powerful tool that can be leveraged to increase the recall of your search system, but there are many subtleties that are important to know and experiment with, especially in conjunction with systematic relevance testing.
The new API to reload search-time analyzers that was added in Elasticsearch 7.3 makes this kind of experimentation easier by not requiring that you close and reopen the index like in the past, and it also provides ways of updating synonym rules that are applied at search time without needing to take your indices offline. This, however, is only one step in a series of improvements that we want to introduce to make managing synonyms across a large cluster friendlier for users. Let us know what you think and drop us some feedback or questions in our Discuss forum. Until then, happy analyzing*!
* Ironically, there is no synonym for this usage of “analyzing”…
Synonyms relate queries together that contextually have the same meaning in your dataset.
Sometimes users will use different terminology than your context might expect.
This can lead them to poor search relevance: you are selling movies, but they want films!
The Synonym feature builds synonym sets. A synonym set contains two or more queries that have similar meaning.
The queries can be synonyms, but they do not need to be.
Each item within a synonym set is a query. A query can be a string made up of one or more words.
Once a synonym set has been created, it will be applied to all future queries.
You can create them via the API or the Dashboard.
A synonym set can contain up to 32 words.
You may construct, list, or delete synonym sets using the /synonyms API endpoint.
Example
curl -X POST '<ENTERPRISE_SEARCH_BASE_URL>/api/as/v1/engines/national-parks-demo/synonyms'
-H 'Content-Type: application/json'
-H 'Authorization: Bearer private-xxxxxxxxxxxxxxxxxxxx'
-d '{
"synonyms": ["summit", "peak", "cliff", "mountain"]
}'
Example Response
{
"id": "syn-33dh34689rre8994g5h94i0nf4",
"synonyms": [
"summit",
"peak",
"cliff",
"mountain"
]
}
Each synonym has a unique id which you can use to display or delete the synonym set after it has been created.
See the Synonyms API Reference for further information.
To manage synonyms through the App Search dashboard, see the following video walkthrough:
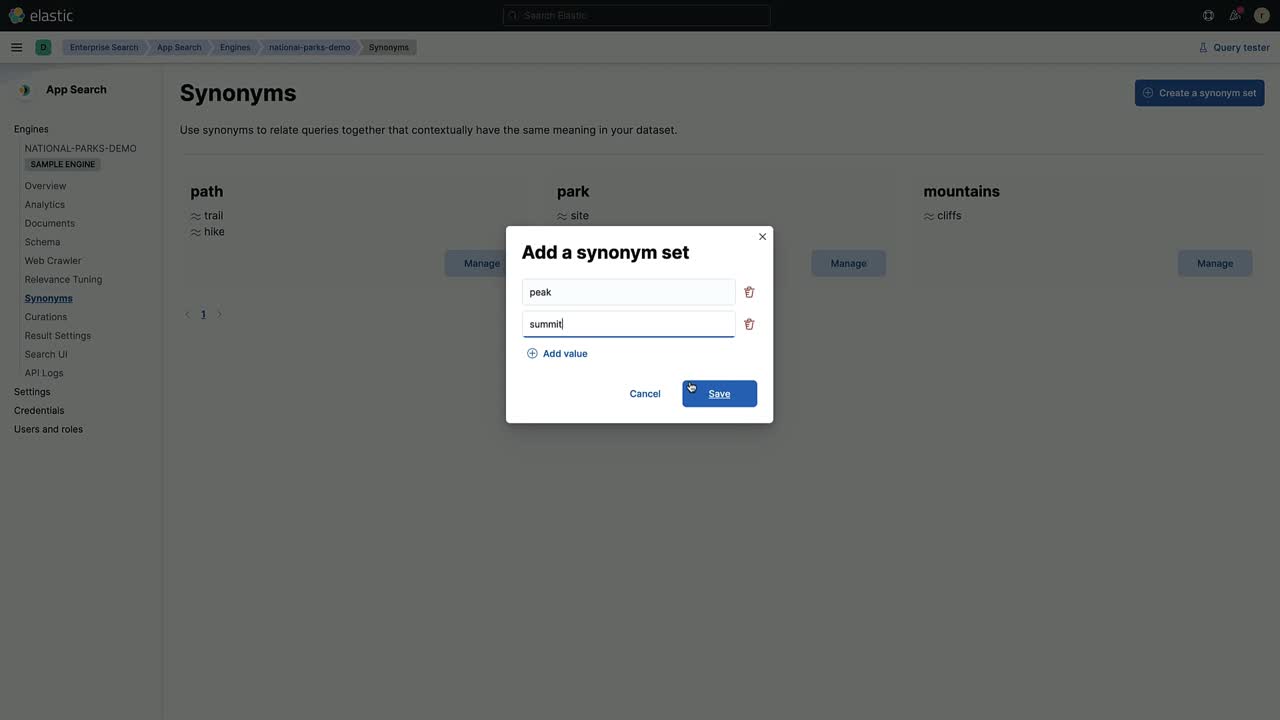
Or, review the following instructions:
Within the dashboard, click into an Engine.
The Engine navigation menu has Search Settings section.
Under it you will find Synonyms alongside Curations and Relevance Tuning. Click into Synonyms.
Next, select Create a Synonym Set and then enter an assortment of queries.
Synonyms — A synonym set within the dashboard.
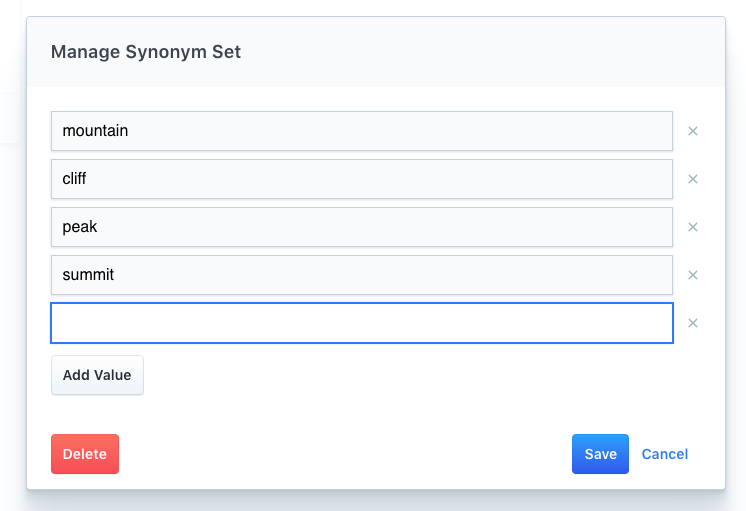
Once you click Save, the synonym set will be applied.
To remove the synonym set, click Manage, then Delete.
The moment it is deleted, the set will no longer influence your search results.
Configuring Synonyms is a useful way to guide your users to the most relevant content. It is most useful when you know the precise terms that they are searching for. For that, you should explore the Analytics and Clickthrough end-points, so that you are aware of your insightful capabilities. If you are looking to provide even more precise and curated results, venture to the Curations end-point.
- Analytics
- Clickthrough
- Curations
20 февр. 2018 г.

Это вторая статья из цикла про Elastic Search. Речь пойдет о настройках синонимов Elastic Search.
Синонимы нужны в том случае, если у нас есть несколько слов, которые морфологически не похожи друг на друга, но при этом имеют сходное значение.
Или это может быть профессиональный жаргон. Примеры: Углошлифовальная машина — болгарка, Отвертка — шуруповерт и т.д.
Стартовая проверка
Все настройки проводились на Elastic Search 6.1.2. Запускалось в Docker.
docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:6.1.0-->
Проверка версии:
http://localhost:9200/
{
"name": "kPe0CUN",
"cluster_name": "docker-cluster",
"cluster_uuid": "htl0xwdDTgSzipAJgSfLmw",
"version": {
"number": "6.1.2",
"build_hash": "5b1fea5",
"build_date": "2018-01-10T02:35:59.208Z",
"build_snapshot": false,
"lucene_version": "7.1.0",
"minimum_wire_compatibility_version": "5.6.0",
"minimum_index_compatibility_version": "5.0.0"
},
"tagline": "You Know, for Search"
}
Впринципе это все должно так же работать и на других версиях, но возможны изменения.
Создание синонимов
Синонимы включаются в настройки индекса. Также есть возможность указать текстовый файл.
Но мне этот вариант показался не таким удобным. Хотя, возможно, он имеет свои преимущества.
Создаем индекс:
curl -X PUT http://localhost:9200/product -H 'Content-Type: application/json' -d '{ "settings": { "analysis": { "filter": { "my_synonym_filter": { "type": "synonym", "synonyms": [ "шуруповерт, отвертка" ] }, "ru_stop": { "type": "stop", "stopwords": "_russian_" }, "ru_stemmer": { "type": "stemmer", "language": "russian" } }, "analyzer": { "my_synonyms": { "tokenizer": "standard", "filter": [ "lowercase", "my_synonym_filter", "ru_stop", "ru_stemmer" ] } } } } }'
Создаем маппинг
curl -X PUT http://localhost:9200/product/_mapping/type -H 'Cache-Control: no-cache' -H 'Content-Type: application/json' -H 'Postman-Token: 98d28f1a-665b-3e26-948b-10b789a6ffce' -d '{ "properties": { "id": { "type": "integer" }, "sku": { "type": "text", "index": true, "search_analyzer": "my_synonyms", "analyzer": "my_synonyms", "term_vector": "with_positions_offsets_payloads" }, "name": { "type": "text", "index": true, "search_analyzer": "my_synonyms", "analyzer": "my_synonyms", "term_vector": "with_positions_offsets_payloads" }, "description": { "type": "text", "index": true, "search_analyzer": "my_synonyms", "analyzer": "my_synonyms", "term_vector": "with_positions_offsets_payloads" }, "price": { "type": "double" }, "created_at": { "type": "text", "index": true, "search_analyzer": "my_synonyms", "analyzer": "my_synonyms", "term_vector": "with_positions_offsets_payloads" }, "updated_at": { "type": "text", "index": true, "search_analyzer": "my_synonyms", "analyzer": "my_synonyms", "term_vector": "with_positions_offsets_payloads" } } }'
Добавление данных
Добавляем продукты:
curl -X PUT http://localhost:9200/product/type/1 -H 'Cache-Control: no-cache' -H 'Content-Type: application/json' -H 'Postman-Token: c99dcbcc-5f1f-4806-b941-db54d7fc2dfb' -d '{ "id": 1, "sku": "ИНТЕРСКОЛ ОА-3,6Ф", "name": "Отвертка аккумуляторная ИНТЕРСКОЛ ОА-3,6Ф блистер (433.0.2.00)", "description": "Отвертка аккумуляторная ИНТЕРСКОЛ ОА-3,6Ф блистер (433.0.2.00) li-ion Номинальное напряжение, В 3,6 Частота вращения, об/мин 210 Макс. Крутящий момент, Нм 5 Число ступеней регулировки крутящего момента 15+1 Масса, кг 0,5 Особенности: Технология Li-ion, Редуктор с металлическими пластинами, компактность, светодиодный фонарь, индикатор заряда, LED-подсветка.", "attribute_set_id": 4, "price": 100, "created_at": "2017-12-04 10:08:12", "updated_at": "2017-12-27 10:28:36" }'
curl -X PUT http://localhost:9200/product/type/2 -H 'Cache-Control: no-cache' -H 'Content-Type: application/json' -H 'Postman-Token: 93c262a5-6acc-b48c-4547-1596f2484534' -d '{ "id": 2, "sku": "Шуруповерт HAMMER", "name": "Шуруповерт HAMMER", "description": "Шуруповерт HAMMER", "attribute_set_id": 4, "price": 100, "created_at": "2017-12-04 10:08:12", "updated_at": "2017-12-27 10:28:36" }'
Поиск
И так, у нас есть 2 продукта с разными названиями. Совпадений нет. Зато у нас есть настроенные синонимы.
Пробуем искать по синонимам:
curl -X POST http://localhost:9200/product/type/_search -H 'Content-Type: application/json' -d '{ "query": { "multi_match": { "query": "Отвертка" } } }'
curl -X POST http://localhost:9200/product/type/_search -H 'Content-Type: application/json' -d '{ "query": { "multi_match": { "query": "Шуруповерт" } } }'
В обоих случаях возвращаются оба продукта. Значит синонимы работают корректно.
Обновление синонимов
Вероятно в процессе работы нам захочется добавить новые синонимы. И, возможно, захочется делать это автоматически.
Чтобы не нужно было перезапускать elastic, лезть в консоль, перезаливатьь данные, пересоздавать индекс и т.д.
Правда все же придется остановить индекс. Добавить синонимы, потом запустить снова. Но, к счастью, это происходит почти моментально.
Закрываем индекс:
curl -X POST http://localhost:9200/product/_close -H 'Content-Type: application/json'
Обновляем синонимы
curl -X PUT http://localhost:9200/product/_settings -H 'Content-Type: application/json' -d '{ "settings": { "analysis": { "filter": { "my_synonym_filter": { "type": "synonym", "synonyms": [ "шуруповерт, шурик, отвертка" ] } } } } }'
Открываем индекс
curl -X POST http://localhost:9200/product/_open -H 'Content-Type: application/json'
Проверка
Мы добавили новый синоним «шурик» — жаргон. Теперь пробуем искать по нему.
curl -X POST http://localhost:9200/product/type/_search -H 'Cache-Control: no-cache' -H 'Content-Type: application/json' -H 'Postman-Token: d9d21a6d-07ff-9b29-e080-87f95c5ecddf' -d '{ "query": { "multi_match": { "query": "шурик" } } }'
Также возвращаются оба продукта. Обновление синонимов прошло успешно.
Все запросы из статьи оформлены в виде Postman коллекции.
Скачать можно тут: elastic_synonyms.postman_collection.json
На этом пока все. Спасибо за внимание!
Всем привет! Меня зовут Евгений Радионов, я бэкенд-разработчик, последние два года пишу на языке Go, до этого работал с Ruby. За это время столкнулся со множеством интересных и сложных задач, в одной из которых и познакомился с ElasticSearch. В этой статье мы разберем, как настроить продвинутый полнотекстовый поиск с использованием ElasticSearch и — в качестве бонуса — интегрировать его в приложение на Go.
Информация будет интересна как начинающим в работе с ElasticSearch, так и продвинутыми пользователям, которые хотят закрепить знания в этой теме. И узнать о подходах, которые помогут в повседневной работе.
Сначала хочу ознакомить вас со структурой статьи. Она разделена на три раздела, первый из которых расскажет о базовых принципах работы полнотекстового поиска, его возникновении и покажет, как можно построить неплохой полнотекстовый поиск на базе PostgreSQL.
Второй, основной и самый большой раздел посвящен ElasticSearch, принципам его работы, разным подходам к описанию настроек индекса и вариантам написания запросов.
Третий, бонусный раздел расскажет о том, как можно интегрировать ElasticSearch в приложение на Go так, чтобы это было удобно поддерживать и расширять.
Почему ElasticSearch
На старте одного из проектов в компании, с которой я сотрудничаю, возник вопрос о реализации полнотекстового поиска с фильтрацией и поиском объектов по их геопозиции в дальнейшем. Один вариант для реализации такой задачи — это PostgreSQL, с его возможностями полнотекстового поиска и фильтрации, а поддержку работы с пространственными данными можно обеспечить расширением PostGIS.
Однако такое решение вряд ли будет работать быстро, да и поддерживать его не очень удобно. Другой вариант — ElasticSearch: инструмент, зарекомендовавший себя как поисковый движок с большим количеством возможностей и настроек для полнотекстового поиска, фильтрации, с поддержкой работы с пространственной составляющей данных и множеством других полезных (и не очень) функций. Можно рассмотреть и прочие альтернативы поисковых движков, но вряд ли начать работать с ними будет так же просто, как с ElasticSearch.
Не стоит забывать о поддержке того или иного инструмента в языке программирования (посредством библиотек), возможности и простоте его развертывания и масштабирования внутри инфраструктуры. Не думаю, что кто-то хотел бы потратить много времени на интеграцию чего-либо, а затем узнать, что поддержка прекратится через три месяца. Забегая наперед, скажу, что выбор в пользу ElasticSearch оказался оправданным и позволил не только построить качественный поиск с релевантной выдачей, но и сделать его быстрым.
Немножко поисковой истории
Перед тем как перейти непосредственно к полнотекстовому поиску и ElasticSearch, давайте ненадолго вернемся в прошлое и посмотрим, с чего все начиналось.
Самый простой способ что-нибудь найти — это перебрать все доступные записи и сравнить значения интересующих нас полей с поисковым запросом в надежде увидеть полное совпадения поля и запроса. Например, если необходимо найти всех клиентов, имя которых John, а фамилия Smith, то на языке SQL это может выглядеть так:
SELECT * FROM customers WHERE first_name = 'John' AND last_name = 'Smith'
Однако мы не всегда точно знаем, как зовут человека или как правильно пишется его имя/фамилия. В таком случае применим поиск с использованием символа подстановки (wildcard search). Так, например, чтобы найти все книги про Гарри Поттера, выполним такой запрос:
SELECT * FROM books WHERE name LIKE 'Harry Potter%'
Подобные запросы хорошо справляются с задачей найти группу записей, объединенных общим критерием: у нас это книги, названия которых начинаются на (имеют префикс) Harry Potter, но при таком подходе проблема с орфографически неправильным написанием (имени, фамилии, названия произведения) остается.
Если продолжать рассматривать варианты в PostgreSQL, то на помощь может прийти поиск с использованием триграмм (trigram).
Поиск с использованием триграмм
Триграмма — это частный случай n-граммы (n-gram), где n = 3, а, в свою очередь, n-грамма — это непрерывная последовательность из n-элементов из заданного образца текста или речи. Изменяя значение n, получаем юниграммы (unigram, n = 1), биграммы (bigram, n = 2), триграммы (trigram, n = 3) и так далее.
В биологии и химии существует похожее понятие — k-мер (k-mer), однако вместо числовых приставок, взятых из английского языка, там используются приставки из греческого. Так получаются знакомые некоторым названия: мономер (monomer, k = 1), димер (dimer, k = 2), и знакомый миллионам полимер (от греч. πολύ «много» + μέρος «часть»), состоящий из множества частей.
Чтобы было проще разобраться с n-граммами, рассмотрим небольшой пример разбиения фразы the quick red fox jumps over the lazy brown dog на триграммы.
Разбить предложение (строку) на триграммы можно на уровне слов (word-level) или на уровне символов (character-level). В таблице ниже — результат таких операций, где «_» означает пробел.
| Word-level | Character-level («_» is space) |
| the quick red quick red fox red fox jumps fox jumps over jumps over the over the lazy the lazy brown lazy brown dog |
the he_ e_q _qu qui uic ick ck_ k_r _re red |
Используя триграммы, можно подсчитать схожесть (similarity) двух строк как количество общих триграмм. Эта простая идея оказывается эффективной для измерения сходства слов во многих естественных языках.
Чтобы сделать это в PostgreSQL, нужно подключить расширение pg_trgm, создать таблицу и добавить индекс с триграммами:
CREATE EXTENSION IF NOT EXISTS "pg_trgm"; CREATE TABLE test_trgm (t text); CREATE INDEX trgm_idx ON test_trgm USING GIST (t gist_trgm_ops);
Тогда для поиска используем следующий запрос:
SELECT t, similarity(t, 'word') AS sml FROM test_trgm WHERE t % 'word' ORDER BY sml DESC, t;
В результате получим значения текстового столбца t, уровень схожести (от 0 до 1) текста из этого столбца и слова word, при этом будут возвращены только те записи, схожесть которых выше порогового значения схожести t % ’word’ (устанавливается в настройках расширения pg_trgm.similarity_threshold).
Полнотекстовый поиск в PostgreSQL
Чтобы воспользоваться всеми возможностями PostgreSQL по полнотекстовому поиску, нужно применить такие типы, как tsvector и tsquery, которые конвертируют хранимые и входящие данные в формат, наиболее подходящий для полнотекстового поиска.
SELECT to_tsvector('The quick brown fox jumped over the lazy dog.');
to_tsvector
-------------------------------------------------------
'brown':3 'dog':9 'fox':4 'jump':5 'lazi':8 'quick':2
Из примера выше мы видим, что в представлении tsvector наша входная строка немного преобразилась. Первое, что бросается в глаза, — это измененный порядок слов и наличие порядкового номера напротив каждого из них. Если рассмотреть подробнее результаты преобразования, можно заметить, что слова The и over куда-то потерялись, а jumped и lazy заменены на jump и lazi соответственно.
В первом случае мы отбросили ненужные (незначимые) для поиска слова, а во втором — преобразовали их в формы, более подходящие для полнотекстового поиска (убрали шум). Запомните это поведение формата tsvector, оно понадобится, когда будем рассматривать составляющие анализатора (analyzer) в ElasticSearch.
Для того чтобы выполнить запрос на полнотекстовый поиск в PostgreSQL, нужно воспользоваться одним из операторов, например @@, который возвращает true, если tsvector (документ) совпадает с tsquery (запросом). Следующие запросы вернут true:
SELECT to_tsvector('The quick brown fox jumped over the lazy dog') @@ to_tsquery('foxes');
SELECT to_tsvector('The quick brown fox jumped over the lazy dog') @@ to_tsquery('jumping');
SELECT to_tsvector('fat cats ate fat rats') @@ to_tsquery(fat & rat);
Так как полнотекстовый поиск в PostgreSQL — это тема для отдельной статьи, подробнее прочитать про него можно в документации, а мы будем переходить непосредственно к ElasticSearch.
Введение в ElasticSearch
ElasticSearch — это распределенный поисковый и аналитический движок с открытым исходным кодом, написанный на Java, который поддерживает большое количество типов данных, включая текстовые, числовые, геопространственные, структурированные и неструктурированные.
Это, по сути, документоориентированная база данных, оптимизированная под всевозможные операции поиска. Понимая это и имея базовое представление о концепциях документоориентированного подхода к хранению данных, становится немного проще разобраться в инструменте.
За годы успешного существования на рынке (первая версия вышла в 2010 году) ElasticSearch стал центральным элементом экосистемы Elastic: ELK Stack. ELK — это акроним трех продуктов компании Elastic: ElasticSearch (поисковый и аналитический движок), Logstash (конвейер обработки данных) и Kibana (интерфейс для визуализации данных). Сегодня можно выделить два самых популярных сценария использования ElasticSearch:
- движок для полнотекстового поиска;
- хранилище логов и метрик в ELK Stack.
В статье мы настроим полнотекстовый поиск в ElasticSearch и немного затронем Kibana для повышения удобства разработки, просмотра и отладки поисковых запросов и их результатов.
Начало работы с ElasticSearch
Перед началом работы еще немного теории. Идея создания ElasticSearch состоит в том, чтобы предоставить возможности библиотеки полнотекстового поиска Apache Lucene для Java пользователям других языков через простой и понятный всем интерфейс: JSON поверх HTTP. Так что все запросы представляют собой JSON, а передаются через HTTP и сегодня. Для исполнения запросов из примеров можно взять любой HTTP-клиент, будь то Postman или cURL. Но я рекомендую воспользоваться Dev Tools в Kibana, хотя бы потому, что там есть автокомплит запросов и подсветка синтаксиса.
Итак, чтобы начать использовать ElasticSearch, вам нужно развернуть его кластер. Проще всего это сделать с помощью docker-compose, заодно запустив Kibana:
version: "2" services: elasticsearch: image: 'docker.elastic.co/elasticsearch/elasticsearch:7.4.0' container_name: 'elasticsearch' ports: - 9200:9200 environment: discovery.type: single-node kibana: image: 'docker.elastic.co/kibana/kibana:7.4.0' container_name: 'kibana' ports: - 5601:5601 environment: SERVER_NAME: kibana.my-organization.com ELASTICSEARCH_URL: http://elasticsearch:9200
ElasticSearch — гибкий инструмент, который работает по принципу «включено все, что тебе не нужно, пока ты это не выключишь». Например, если индекса не существует, то он будет автоматически создан при вставке первой записи.
Индекс — это коллекция документов, которые обычно имеют одинаковую структуру данных, хотя это не обязательно. Объединяя документы в коллекции (индексы), мы можем сгруппировать похожие данные в одном месте для последующего поиска по ним.
Хоть мы уже можем добавлять данные в ElasticSearch:
PUT /books_index/_doc/1
{
"name": "Harry Potter and the Philosopher's Stone",
"publishing_year": 1997,
"author": {
"name": "J. K. Rowling"
}
}
Я рекомендую начать с определения формата хранимых данных (mapping) в индексе, если это возможно.
Давайте рассмотрим небольшой пример простого поиска на базе индекса для книг:
PUT /books_index // Create index first
PUT /books_index/_mappings
{
"properties": {
"name": {
"type": "text"
},
"publishing_year": {
"type": "integer",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"author": {
"properties": {
"name": {
"type": "text"
}
}
}
}
}
Объявляя mapping, мы описываем не только структуру хранимых данных в нашем индексе, но и правила поиска для конкретных полей, которые рассмотрим немного позже. А пока добавим еще один документ в индекс (не забудьте добавить первый документ):
PUT /books_index/_doc/2
{
"name": "The Great Gatsby",
"publishing_year": 1925,
"author": {
"name": "F. Scott Fitzgerald"
}
}
В итоге мы создали индекс books_index, в котором будем хранить информацию о книгах и их авторах, и добавили два документа для поиска.
Обратите внимание, что поля документа, которые будут сохранены, имеют собственный тип (text, integer), могут быть другими вложенными объектами со своими полями (author), а также иметь подполя (fields). Если со вложенными объектами все понятно, то вот с подполями, или, как они называются в документации, multi-fields, возникают вопросы.
Подполя нужны для того, чтобы проиндексировать одно и то же значение в разных форматах данных. Например, если хотим добавить возможность полнотекстового поиска для поля типа boolean (этот случай мы рассмотрим позже) или типа integer (хотя в данном случае это не обязательно), то можно объявить подполя типа text, и в момент вставки значение будет приведено к этому типу и сохранено в подполе.
Сразу отмечу, что поля типа keyword и text с виду похожи, но используются для разных целей. И важно понимать разницу: keyword — для поиска по полному совпадению, в то время как text — для полнотекстового поиска, то есть по частичному совпадению. Более подробно мы рассмотрим это позже, когда будем разбираться с анализаторами.
Теперь, когда у нас есть несколько документов в индексе, попробуем по ним поискать. Один из самых мощных запросов для полнотекстового поиска — это запрос query_string:
GET /books_index/_search
{
"query": {
"query_string": {
"query": "harry"
}
}
}
GET /books_index/_search
{
"query": {
"query_string": {
"query": "1925"
}
}
}
В первом случае будет найдена книга Harry Potter and the Philosopher’s Stone, а во втором — The Great Gatsby. Давайте более подробно разберем ответ, который получили от ElasticSearch:
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.105360515,
"hits" : [
{
"_index" : "books_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.105360515,
"_source" : {
"name" : "Harry Potter and the Philosopher's Stone",
"publishing_year" : 1997,
"author" : {
"name" : "J. K. Rowling"
}
}
}
]
}
Первым нас встречает total, он показывает, сколько документов, соответствующих нашему запросу, было найдено (value). Но есть нюанс: по умолчанию это число считается приблизительно. Чтобы получить точный результат, нужно в запросе указать «track_total_hits»: true или «track_total_hits»: 100, где 100 — количество записей, которые вы хотите точно подсчитать.
Но будьте осторожны: включение этой опции приведет к тому, что ElasticSearch будет «пробегаться» по всем документам в индексе, соответствующим запросу, что непременно скажется на скорости его выполнения. Второй параметр в total — relation: он может принимать либо значение eq (точное количество записей), либо gte (записей больше, чем написано в value).
Далее находится max_score — это максимальное значение _score среди найденных документов. Само же _score показывает, насколько хорошо документ подходит под критерии поиска (больше — лучше). По умолчанию оно колеблется между 0 и 1 для каждого документа, однако есть механизмы, которые позволяют это изменить (boost, tie_breaker).
Я бы советовал не привязываться к каким-то конкретным значениям показателя, так как он носит относительный характер и позволяет понять, насколько хорошо тот или иной документ из результатов выдачи соотносится с конкретным запросом. Еще один важный момент — без указания параметров сортировки поисковая выдача будет отсортирована по показателю _score в порядке убывания, что автоматически поднимет лучшие записи наверх.
Двигаемся дальше. Массив hits, который hits.hits, — это массив документов из выдачи. Наиболее важные параметры в нем — _score, _id и _source. Про _score мы уже говорили, _id — это уникальный идентификатор записи в индексе (указывается при запросе на вставку PUT/books_index/_doc/1, _id = 1). Он хранится как значение строчного типа, так что можно использовать не только числа, но и другие уникальные идентификаторы, например UUID. Поле _source — это те данные, которые были переданы ElasticSearch для вставки, то есть исходный документ.
Анализ и поиск в ElasticSearch
Любой поисковый запрос в ElasticSearch перед непосредственным исполнением попадает в анализатор (analyzer). Analyzer — это конвейер (pipeline), который состоит из нескольких частей: character filter, tokenizer и token filter.

ElasticSearch предоставляет набор встроенных анализаторов для базовых потребностей, однако, скорее всего, вам придется написать собственный.
Разберем принципы работы анализатора на небольшом примере. Для этого нужно добавить в mapping собственный analyzer и назначить его для какого-нибудь поля:
PUT /books_index
{
"settings": {
"analysis": {
"analyzer": {
"customHTMLAnalyzer": {
"type": "custom",
"char_filter": [
"html_strip"
],
"tokenizer": "standard",
"filter": [
"lowercase",
"stop"
]
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "customHTMLAnalyzer"
},
"publishing_year": {
"type": "integer",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"author": {
"properties": {
"name": {
"type": "text"
}
}
}
}
}
}
Объявляем analyzer с именем customHTMLAnalyzer, определяем для него параметры character filters, tokenizer, filters (token filters) и указываем, что для поля имени книги будем использовать его.
Тогда и при вставке, и при поиске для поля документа и поискового запроса будет применено следующие:
- Убрать все HTML-теги из входящей строки (html_strip char filter).
- Разбить входную строку на токены, в данном случае на слова, при этом удаляя знаки пунктуации (standard tokenizer).
- Изменить регистр каждого токена на нижний (lowercase filter).
- Убрать токены, которые являются стоп-словами (spot filter) и не имеют важного значения для поиска. Например, для английского языка это a, an, and, for, if, in, the и так далее.
Tokenizer в ElasticSearch
Начнем подробный разбор анализатора с такой его составляющей, как tokenizer (токенайзер). Он принимает на вход массив символов (обычно текст или поисковую строку), разбивает их на отдельные токены (обычно слова) и передает их дальше в фильтры. Рассмотрим таблицу с наиболее популярными токенайзерами в ElasticSearch, полный список которых можно найти в документации.
| Наиболее популярные токенайзеры | |
| standard | разбивает текст на слова, удаляет знаки пунктуации The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. →[The, 2, QUICK, Brown, Foxes, jumped, over, the, lazy, dog’s, bone] |
| classic | токенайзер, основанный на правилах грамматики английского языка |
| ngram | те самые n-граммы из части про PostgreSQL, разбивает текст на слова, затем каждое слово разбивает на n-граммы quick → [qu, ui, ic, ck] |
| edge_ngram | похож на ngram, тоже разбивает текст на слова, затем каждое слово разбивает на n-граммы, но делает это, сохраняя привязку к началу слова quick → [q, qu, qui, quic, quick] |
| keyword | это токенайзер, который ничего не делает, идеально подходит, когда нужно найти что-то по полному совпадению quick → quick |
Выбирать токенайзер нужно исходя из ваших входных данных и целей, для которых будет использоваться конкретное поле. Например, для полнотекстового поиска хорошо подходят standard (для любого языка) и classic (если планируется поиск только по английскому языку), для поиска по полному совпадению — keyword, для нечеткого (fuzzy) поиска — ngram и edge_ngram, последний — удачное решение для автодополнения (autocomplete или completion suggester, как это называется в ElasticSearch). Кроме этих токенайзеров, есть более специфические: UAX URL Email Tokenizer (uax_url_email) — такой же, как standard, только распознает email и URL-адреса как один токен, или же Path Tokenizer (path_hierarchy), который может построить иерархию пути (например, к файлу): /foo/bar/baz → [/foo, /foo/bar, /foo/bar/baz].
Filters в ElasticSearch
Переходим к фильтрам. Фильтр принимает на вход массив токенов из токенайзера и может их изменять (например, привести к нижнему регистру), удалять (стоп-слова) или добавлять новые (синонимы). Фильтры разделены на две группы: те, которые зависят от языка (отмечены *), и те, которые не зависят. Ключевая разница в том, что для языковых фильтров в их настройках нужно явно указывать язык или по умолчанию будет выбран английский (это поведение вряд ли изменится с приходом новых версий ElasticSearch, но лучше перестраховаться и всегда указывать явно). Соответственно, языковые фильтры для разных языков будут работать немного по-разному и учитывать особенности того или иного языка, чтобы предоставить наиболее релевантное поведение и, как следствие, наиболее релевантную поисковую выдачу.
Важно отметить, что фильтры будут применены в том порядке, в котором указаны в mapping. Поэтому важно следить как за порядком объявления фильтров, так и за их внутренним устройством.
| Наиболее популярные фильтры | |
| lowercase | меняет регистр токена на нижний
«QuIck» → «quick» |
| trim | удаляет пробельные символы в начале и в конце токена
» quick » → «quick» |
| stop* | удаляет стоп-слова, для английского языка это a, an, and, for, if, in, the и так далее |
| stemmer* | stemming — это процесс сокращения слова до его корневой формы. Хоть это и языковой фильтр, но чаще всего включает в себя удаление суффиксов и префиксов из слова.
«the foxes jumping quickly» → [ the, fox, jump, quickli ] |
| conditional | позволяет применять фильтры в зависимости от условия |
Character filters в ElasticSearch
Character filters используются для предварительной обработки текста до того, как он попадет в tokenizer. Встроенных фильтров для этой группы на удивление немного, но они универсальны.
| Character filters | |
| html_strip | удаляет теги HTML, а также декодирует экранированные символы, например <p>I'm so <b>happy</b>!</p>” → “nI'm so happy!n |
| mapping | позволяет определить соответствие»ключ-значение» для последующей замены каждого найденного ключа на соответствующее ему значение |
| pattern_replace | позволяет определить регулярное выражение (на диалекте языка Java) для нахождения символов (pattern), которые должны быть заменены согласно правилу в строке replacement |
Analyze API в ElasticSearch
Для того чтобы было проще разобраться, что происходит с входными данными во время анализа, предусмотрен специальный механизм — Analyze API. Он анализирует конкретный текст с конкретным набором всех составляющих анализатора. Пользоваться им довольно просто и бывает полезно, чтобы понять, почему та или иная запись появляется (или не появляется) в поисковой выдаче и в каком именно виде будет сохранено значение конкретного поля в индексе. Приведу небольшой пример, а более подробно можно ознакомиться с этим механизмом в документации.
| Запрос | Ответ |
GET /_analyze
{
"tokenizer" : "whitespace",
"filter" : [
"lowercase",
{
"type": "stop",
"stopwords": [
"a",
"is",
"this"
]
}
],
"text" : "this is a test"
}
|
{
"tokens" : [
{
"token" : "test",
"start_offset" : 10,
"end_offset" : 14,
"type" : "word",
"position" : 3
}
]
}
|
Типы запросов в ElasticSearch
После того как мы разобрались с тем, как документы будут сохраняться и анализироваться в индексе, можно начинать выполнять поисковые запросы. Запросы — это то, что каждому нужно осваивать индивидуально. Описать универсальный подход к созданию запросов, чтобы они работали в большинстве случаев, невозможно. Я настоятельно рекомендую самостоятельно внимательно и детально изучить механизмы запросов в ElasticSearch, а также изучить то, как и из чего формируется _score документа в процессе запроса. Так что добро пожаловать на страницы документации, а мы проведем небольшой обзор наиболее распространенных типов запросов.
Начнем с понятий контекста запроса и фильтров (да-да, и тут фильтры). По умолчанию ElasticSearch сортирует результаты поиска по оценке релевантности (relevance score) — это то самое поле _score. Однако бывают ситуации, когда нужно произвести поиск внутри группы документов, которые соответствуют общим критериям, например, созданы не раньше определенной даты или которые имеют определенный статус. Здесь на помощь приходят фильтры запросов.
И поисковый запрос (query), и фильтр (filter) принимают на вход запросы в одном формате, но с той лишь разницей, что запросы, написанные внутри filter, не влияют на итоговое значение _score.
Рассмотрим небольшой пример:
GET /books_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "The Great Gatsby"
}
}
],
"filter": [
{
"range": {
"publishing_year": {
"gte": "1900"
}
}
}
]
}
}
}
Вначале будут отобраны те книги, которые опубликованы в 1900 году и позднее (filter), а затем по ним будет произведен поисковый запрос (query).
Резюмируя, можно сказать, что в контексте запроса (query) мы отвечаем на вопрос: «Насколько хорошо тот или иной документ соответствует этому запросу?», а в контексте фильтра (filter): «Стоит ли рассматривать этот документ вообще?».
В примере запроса мы использовали три конструкции: bool, must и match. Рассмотрим их по порядку: bool относится к категории составных (compound) запросов. Составные оборачивают другие составные или простые запросы, чтобы объединить их результаты и оценки (_score), изменить их поведение или переключиться с запроса на контекст фильтрации. Bool-запрос сопоставляет документы, соответствующие логическим комбинациям других запросов. Наиболее близкий пример — это операция WHERE в SQL-запросе, куда тоже можно передать набор логических операций (x < 0 AND y > 5 OR z = 0). В ElasticSearch операциям AND и OR из SQL есть свои аналоги:
| ElasticSearch | SQL |
"bool" : {
"must" : [
"term" : {"id" : 35},
"term": {"age": 18}
]
}
|
SELECT * FROM users WHERE id = 35 AND age = 18 |
"bool" : {
"should" : [
"term" : {"id" : 35},
"term": {"age": 18}
]
}
|
SELECT * FROM users WHERE id = 35 OR age = 18 |
В примере выше мы использовали новый тип запроса term — это аналог = в SQL, то есть наш документ попадет в результаты поиска, если значение из поля полностью совпадает с поисковым значением.
Перед тем как перейти к группе полнотекстовых запросов, давайте рассмотрим запросы на основе точных значений (term-level queries). С их помощью можно быстро найти записи, которые соответствуют точным критериям. Например, значение статуса продукта или его уникальный идентификатор (id), или же диапазон дат и прочее.
Важно отметить, что, в отличие от полнотекстовых запросов, запросы на основе точных значений не анализируют условия поиска (поисковый запрос). Вместо этого они ищут полное соответствие поискового запроса значению, хранящемуся в поле (проанализированному и преображенному при вставке). Поэтому фильтрация по полу типа text может не сработать, я рекомендую использовать подполя (multi-fields) с типом keyword для полей с типом text, если есть необходимость фильтрации и полнотекстового поиска по ним.
| exists | Возвращает документы, содержащие проиндексированное значение для поля — если для поля не выключена индексация (index: false) или оно не null или [] |
| fuzzy | Возвращает документы, похожие на поисковый запрос |
| ids | Возвращает документы с соответствующими _id |
| prefix | Возвращает документы, содержащие определенный префикс в указанном поле |
| range | Возвращает документы, содержащие значения в указанном диапазоне |
| regexp | Возвращает документы, соответствующие указанному регулярному выражению |
| term | Возвращает документы, значение поля которых полностью совпадает с запросом.Аналог WHERE field = 15 |
| terms | Возвращает документы, содержащие одно или несколько точных совпадений в указанном поле.Аналог WHERE field IN (15, 26, 31) |
| terms_set | То же самое, что и terms, но дает возможность указать минимальное число совпадающих значений |
| type | Возвращает документы с указанным типом |
| wildcard | Возвращает документы, соответствующие шаблону с символом подстановки (? и *).Аналог WHERE field LIKE ‘harry%’ |
Переходим к полнотекстовым запросам. Они позволяют выполнять поиск в проанализированных текстовых полях, например в теле электронного письма или названия книги. Строка запроса будет обработана тем же анализатором, который применялся к полю при индексировании.
match возвращает документы, соответствующие указанному тексту, числу, дате или логическому (boolean) значению. Этот тип запроса наиболее простой и наиболее базовый для проведения полнотекстового поиска. С его помощью также можно выполнять нечеткий (fuzyy) поиск. match анализирует входящий запрос, и в процессе анализа создается логический запрос из предоставленного текста. Параметр operator может быть установлен в and или or (по умолчанию or) для управления поведением. Это означает, что с оператором or будут найдены документы, в которых совпадает хотя бы один из токенов, при чем документы с большим числом совпадений будут иметь большее значение _score. А при использовании оператора and необходимо совпадение всех токенов из поискового запроса.
query_string — это швейцарский нож, с помощью которого через ключевые слова и символы можно построить запрос практически любой сложности. Однако применение этого типа запроса требует от разработчика экранирования специальных символов (а их немало), запрещенных пользователю для использования, а также обработки ошибок. Именно этот тип запроса напрямую применяют во вкладке Discover в Kibana.
Он поддерживает все возможности поискового синтаксиса. Например, status:active добавит условие, что поле status должно иметь значение active. Поддерживаются и логические операторы title:(quick OR brown). Также можно использовать символы подстановки qu?ck bro* и регулярных выражений name:/joh?n(ath[oa]n)//. Есть нечеткий поиск quikc~, поиск по диапазону (range), по нескольким полям сразу, группировка и многое другое.
Использование этого типа запроса дает обширные поисковые возможности, однако открывает пользователю доступ ко всем полям в индексе.
К счастью, есть более дружелюбный тип запроса с поддержкой поискового синтаксиса, но и с некоторыми ограничениям — это simple_query_string. Работает он точно так же, как и query_string, однако не возвращает ошибку, если в запросе неправильный синтаксис. Подробнее с отличиями между этими двумя запросами можно ознакомиться в документации.
Синонимы в ElasticSearch
Иногда нужно использовать значение константы или булево значение как значение поля в индексе. Например, мы хотим пометить нашу книгу как книгу лимитированного издания и дать пользователю возможность как-то выделить такие книги при полнотекстовом поиске. Тогда можем задать поле книги «limited_edition»: «limited_edition», но релевантность поисковой выдачи может быть не очень высока, так как при выполнении запроса пользователь получит желаемый результат, только если введет limited_edition. В остальных случаях возможны варианты.
Если же использовать более привычный вариант с полем типа boolean, то как-то описать значимость такого поля в полнотекстовом поиске не представляется возможным. Мы же хотим сделать так, чтобы при вводе таких слов и словосочетаний, как limited, limited edition, deluxe, deluxe edition, special, exclusive и других, пользователь мог увидеть книги из лимитированного издания и, может быть, приобрести их. Для этого понадобятся синонимы.
Синонимы в ElasticSearch — это не что иное, как синонимы в любом естественном языке — разные слова, которые имеют одинаковый смысл, с той лишь разницей, что в разговорной речи понимание синонимов происходит само собой, а в ElasticSearch их нужно явно определить. Для этого в поисковом движке предусмотрен специальный фильтр synonym token filter. Он поддерживает специальный синтаксис объявления синонимов, а также позволяет загрузить их непосредственно из файла. Для задания синонимов лучше использовать один подход: синонимы в файле или в настройках индекса (mapping).
"filter": {
"synonym_filter": {
"type": "synonym",
"synonyms_path": "analysis/synonym.txt",
"lenient": true,
"synonyms": [
"limited, limited edition, deluxe, deluxe edition => limited_edition",
"free, cheap"
]
}
}
Рассмотрим этот пример. Мы создаем фильтр, который называется synonym_filter и имеет тип synonym. Исключительно для примера были использованы оба способа объявления синонимов: для файла это поле synonyms_path и относительный путь к нему, для списка синонимов — массив synonyms. Свойство lenient отвечает за игнорирование ошибок при обработке синонимов.
Есть два основных способа отождествить два слова: простое отождествление, как в нашем примере free, cheap, и отождествление с заменой — при выполнении этого фильтра limited, limited edition, deluxe, deluxe edition будут заменены на константу limited_edition. Это два разных подхода, которые только на первый взгляд работают похожим образом. Нужно понимать, что при использовании нотации со стрелкой (=>) мы заменяем слова из левой части на слова из правой, что означает, что только документы, в которых есть слово из правой части, будут хоть как-то отображены в результатах поиска. Нотация с запятой позволяет отождествить слова. Можно представить это так: если слово совпало с одним из списка, то замените его на весь список. Таким образом документы, которые содержат в себе хотя бы одно из слов-синонимов, будут оценены выше, поэтому будут находиться выше в результатах поиска.
В примере есть одна неточность, точнее особенность. Так как синонимы — это тоже фильтр, то он работает с токенами. И если текст разбивается на токены по пробелам, то многословные синонимы (словосочетания) работать не будут, потому что в самом токене физически не может быть несколько слов, разделенных пробелом.
Чтобы решить эту проблему, можно как-то настроить токенайзер, однако лучше использовать встроенную функцию, предназначенную для таких случаев. Она называется synonym graph token filter.
Синтаксис у synonym graph token filter такой же, как у synonym filter, но работает он немного иначе. Во время работы этого фильтра будет создан graph token stream, то есть он будет обрабатывать не отдельные токены, а их набор. Принципы работы этого фильтра отлично описывает картинка из официальной документации. Если необходимо заменить фразу на ее акроним: domain name system => dns, то выглядит это следующим образом:

Будет найдено словосочетание domain name system и заменено на dns, и последующие фильтры будут работать уже с измененным набором токенов. Возможны варианты, когда будут созданы два подзапроса: для исходного набора токенов и для измененного, например, когда используется match_phrase.
Подробнее узнать про синонимы и граф синонимов можно в документации.
Собираем все вместе
Чтобы получить более наглядную картину того, как все эти настройки уживаются вместе, рассмотрим пример:
{
"index_patterns": [
"book*"
],
"settings": {
"analysis": {
"analyzer": {
"books_analyzer": {
"type": "custom",
"char_filter": [
"html_strip"
],
"tokenizer": "standard",
"filter": [
"lowercase",
"synonym_filter",
"synonym_graph_filter",
"english_possessive_stemmer",
"english_stop"
]
}
},
"filter": {
"english_stop": {
"type": "stop",
"stopwords": "_english_"
},
"english_possessive_stemmer": {
"type": "stemmer",
"language": "possessive_english"
},
"synonym_filter": {
"type": "synonym",
"synonyms": [
"limited, limited edition, deluxe, deluxe edition => limited_edition",
"free, cheap"
]
},
"synonym_graph_filter": {
"type": "synonym_graph",
"synonyms": [
"limited edition, deluxe edition => limited_edition"
]
}
}
}
},
"mappings": {
"dynamic": false,
"date_detection": false,
"properties": {
"name": {
"type": "text",
"analyzer": "books_analyzer"
},
"publishing_year": {
"type": "integer",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"author": {
"properties": {
"name": {
"type": "text",
"analyzer": "books_analyzer"
}
}
},
"limited_edition": {
"type": "text",
"analyzer": "books_analyzer",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
}
Мы объявили шаблон индексов, который после добавления будет автоматически применяться ко всем индексам, имя которых начинается с book. Задали свой анализатор, который уберет все HTML-теги из входного текста, затем разобьет его на токены по пробелам, а также уберет символы пунктуации. После этого поля, для которых указано использование анализатора, будут следовать указанным правилам анализа.
Немного хитростей для удобства
Перед переходом к следующему разделу, давайте уделим еще немного времени ElasticSearch и рассмотрим несколько его возможностей, которые облегчают жизнь.
Первая из них — это шаблоны индексов (index templates). Они позволяют описать настройки индекса и задать имена или паттерны имен индексов, при создании которых будет применен этот шаблон. Подробнее в документации.
Вторая — псевдоним (alias) индекса. Он работает по принципу указателя в языке программирования: указывает на конкретный индекс и может быть в любой момент изменен, чтобы указывать на другой. Таким образом, работая с индексом посредством псевдонима, можно писать код, не опасаясь, что изменение имени индекса приведет к изменению кода.

Используя два предыдущих подхода, можно реализовать третий: переиндексацию без даунтайма. Переиндексация документов может быть полезна как во время разработки, когда mapping индекса меняется, так и когда вашим приложением уже пользуются, а вы хотите добавить новые поисковые возможности или изменить поведение старых.
Опишем этот процесс:
- Обновить шаблон индексов.
- Создать новый индекс из шаблона.
- Добавить все данные из базы данных в новый индекс, во время этого процесса все изменения над данными должны записываться в два индекса (в alias и в новый индекс).
- Переключить alias на новый индекс.
- Удалить старый индекс.
И последние две настройки, которые позволят вам выделить другие поля в документе на фоне остальных при полнотекстовом поиске: boost и tie_breaker. Опцию boost (по умолчанию = 1) можно указывать как для полей, так и для запросов/подзапросов. Если она задана, то _score поля или запроса будет умножен на ее значение: _score = original _score * boost.
tie_breaker указывается для запроса, причем не каждый запрос его поддерживает, значение его может быть в пределах от 0.0 до 1.0 и работает он так: если его значение >0.0 (по умолчанию = 0.0), то финальное значение документа считается следующим образом:
- Выбрать _score наиболее подходящего поля.
- Умножить _score остальных полей, подходящих под критерии поиска на tie_breaker.
- Сложить и нормализировать полученные результаты.
С этой опцией можно выделить те документы, которые содержат один и тот же токен в разных полях.
Используя boost и tie_breaker, можно сделать акцент полнотекстового поиска на нужных вам полях, а также определить роль второстепенных полей.
Еще пару слов про ElasticSearch
В заключение этого раздела отмечу, что настройка mapping, фильтров, анализатора и всех остальных составляющих поискового движка — это индивидуальная процедура для каждой конкретной задачи, набора данных и пожеланий по работе поиска, фильтрации, сортировки и так далее. Не стоит забывать, что настройка правил хранения и анализа данных в индексе — это только половина дела, вторая половина — подбор наиболее подходящих поисковых запросов. Все это невозможно без понимания принципов работы этого мощного инструмента, так что экспериментируйте, ошибайтесь, изучайте, оптимизируйте и пробуйте снова. Настройка филигранного поиска — это длительный процесс, поэтому запаситесь терпением и не забывайте записывать свои отзывы и отзывы коллег о качестве поиска. И, самое главное, постарайтесь узнать, что о нем думают драгоценные пользователи.
Бонусный раздел: интеграция ElasticSearch в приложение на Go
Для работы с ElasticSearch в Go я использую библиотеку github.com/olivere/elastic/v7. Перед тем как отправить запросы в ElasticSearch, нужно к нему подключиться:
options := []elastic.ClientOptionFunc{
elastic.SetURL("http://localhost:9200"),
}
cli, _ := elastic.NewClient(options...)
В этом и всех последующих примерах ошибки не обрабатываются для краткости, однако в реальных проектах так делать не стоит.
После этого можно создать шаблон индекса и сам индекс, а также добавить к нему псевдоним:
body, _ := ioutil.ReadFile("path/to/index/template.json")
cli.IndexPutTemplate("books_template").BodyString(string(body)).Do(ctx)
cli.CreateIndex("books_index_1").BodyString("").Do(ctx)
cli.Alias().Add("books_index_1", "books_index").Do(ctx)
Как видите, если используется шаблон индекса, то при создании самого индекса его настройки можно не передавать.
Это лучше проделывать на старте приложения, чтобы в дальнейшем быть уверенными, что все готово к работе. Также не лишним будет проверить, существует ли индекс, перед его созданием:
exists, err := cli.IndexExists("books_index_1").Do(ctx)
И не создавать его, если в этом нет необходимости.
Для шаблонов такую операцию можно не проводить, они будут просто обновлены до нужного состояния.
На этом этапе уже можно как добавлять новые документы в индекс, так и искать по ним, однако давайте остановимся и попробуем написать удобный интерфейс для составления сложных запросов. Для этого обратимся к шаблону проектирования Builder.
type QueryBuilder struct {
q *elastic.BoolQuery
}
func NewQueryBuilder() *QueryBuilder {
return &QueryBuilder{
q: elastic.NewBoolQuery(),
}
}
func (b QueryBuilder) Query() elastic.Query {
return b.q
}
Корневым запросом у нас будет boolean query, на базе которого можно построить разные вариации как поиска, так и фильтрации. Для начала объявим метод для полнотекстового поиска:
func (b *QueryBuilder) Search(query string) *QueryBuilder {
b.q = b.q.Should(
elastic.NewQueryStringQuery(query).Boost(2).DefaultOperator("AND").TieBreaker(0.4),
elastic.NewQueryStringQuery(query).Boost(1).DefaultOperator("OR").TieBreaker(0.1),
)
return b
}
В нем мы используем запрос типа query_string (не забываем про экранирование спецсимволов или альтернативы этому запросу в виде simple_query_string или match), объединим (используя should) документы, которые лучше соответствуют поисковому запросу, с теми, которые соответствуют ему хуже. Для документов, в которых совпало больше токенов (default operator AND), мы умножим их _score на 2 (boost), а также увеличим влияние других полей (tie_breaker) на результат. А для документов, которые совпали не идеально с поисковым запросом (90% случаев), в поле boost явно зададим значение по умолчанию 1 и совсем немного увеличим влияние других полей.
Таким образом мы сильно поднимаем вверх выдачи те документы, которые хорошо совпали с поисковым запросом, что повышает шанс показать пользователю именно то, что он хочет, и в то же время даем ему и другие подходящие результаты.
Сделаю ремарку, что запись b.q = b.q.Should(…), то есть переприсваивание результатов выполнения, не является обязательной, так как в этой библиотеке для работы с ElasticSearch построение запросов модифицирует внутренний объект и возвращает его же в качестве результата. При написании b.q.Should(…) без переприсвоения мы неявно модифицируем объект q посредством библиотеки. Следовать тому или иному подходу — решать вам, я же предпочитаю явные объявления, поэтому и в дальнейших примерах буду использовать вариант с переопределением.
Чтобы добавить объект в индекс, можно воспользоваться следующей командой:
cli.Index().Index("books_index").Id(1).BodyJson(book).Do(ctx)
Где book — это наш объект, например структура, которая будет сериализована в JSON внутри метода BodyJson и добавлена в индекс, на который указывает псевдоним books_index.
Что, если мы захотим отфильтровать книги по какому-то признаку, например по автору или тому, является ли издание лимитированным.
func (b *QueryBuilder) Author(name string) *QueryBuilder {
b.q = b.q.Filter(elastic.NewTermQuery("author.name", name))
return b
}
Можно сделать практически то же самое, но чтобы результаты фильтрации влияли на _score.
func (b *QueryBuilder) TermQuery(termKey, termValue string) *QueryBuilder {
b.q = b.q.Must(elastic.NewTermQuery(termKey, termValue))
return b
}
Меняя Filter на Must, можно быстро и просто корректировать поведения поиска. А на базе такого запроса просто построить другой запрос, который позволит отфильтровать по полям, для которых было применено сочетание text + keyword (в нашем случае это limited_edition).
func (b *QueryBuilder) BoolKeywordQuery(termKey, termValue string) *QueryBuilder {
return b.TermQuery(termKey+".keyword", termValue)
}
Как видите, обращение осуществляется так же, как и к вложенному объекту — через точку.
Запрос типа terms может выглядеть так:
func (b *QueryBuilder) TermsQuery(termKey string, vals []interface{}) *QueryBuilder {
if len(vals) == 0 {
return b
}
b.q = b.q.Must(elastic.NewTermsQuery(termKey, vals...))
return b
}
А типа range для числовых значений — следующим образом:
func (b *QueryBuilder) RangeQuery(termKey string, min, max int) *QueryBuilder {
if min == 0 && max == 0 {
return b
}
var rangeQuery = elastic.NewRangeQuery(termKey)
if min != 0 {
rangeQuery = rangeQuery.Gte(min)
}
if max != 0 {
rangeQuery = rangeQuery.Lte(max)
}
b.q = b.q.Must(rangeQuery)
return b
}
Комбинируя разные запросы и добавляя новые слои абстракции над ними, получим удобный инструмент для написания сложных запросов простым способом.
Выполнить любой запрос можно так:
query := NewQueryBuilder().
Search("harry potter limited edition").
TermQuery("author.name", "J. K. Rowling").
RangeQuery("publishing_year", 1990, 2001).
Query()
cli.Search().
Index("books_index").
From(offset).
Size(limit).
Query(query).
Do(ctx)
Здесь limit и offset — это параметры пагинации, так как по умолчанию результаты поискового запроса отсортированы в порядке убывания параметра _score, то явным образом сортировку можно не указывать, однако и это возможно.
В процессе настройки и отладки полезно посмотреть запрос, который выполняется. Для этого добавим еще один метод в строителе запроса:
func (b *QueryBuilder) DebugPrint() {
fmt.Printf("=================n= DEBUG START =n=================n")
source, _ := b.Query().Source()
sourceJson, _ := json.Marshal(source)
fmt.Printf("Query:n%sn", string(sourceJson))
fmt.Printf("=================n= DEBUG END =n=================n")
}
Что осталось за кадром
Вот мы и подошли к концу статьи, для кого-то неожиданно быстро, а для кого-то неожиданно медленно. Напоследок хочу описать те важные моменты, что не попали в материал.
Во-первых, это внутреннее устройство принципов работы полнотекстового поиска в ElasticSearch, во-вторых — настройка, мониторинг и масштабирование его кластера.
Касательно самого ElasticSearch и его поисковых возможностей, то тут стоит обратить внимание на:
- работу с сортировкой: для простых случаев она выполняется легко, но для более сложных — местами, нетривиально;
- работа с агрегациями: агрегации — мощный инструмент в ElasticSearch, который позволяет не только заменить GROUP BY в SQL, но и превзойти его;
- работа с вложенными полями: хоть мы и рассмотрели примеры по работе с вложенными объектами, однако не всегда вложенные поля — это объекты. Это могут быть и массивы. И работа с ними может оказаться неочевидной, особенно когда нужно осуществить сложную выборку и сортировку;
- автодополнение (completion suggester) — тоже отдельная тема для разговора и изучения.
Послесловие
Вот и настало время прощаться. Спасибо вам за ваше время, проведенное за чтением статьи, надеюсь, вы потратили его с пользой. Хотелось бы еще раз сказать, что настройка качественного и быстрого поиска — это длительный процесс, так что запаситесь терпением, ищите, ошибайтесь, учитесь, развивайтесь, адаптируйтесь, эволюционируйте.

![]()
Похожие статьи:
Ссылки, на которые лучше таки нажать (по мнению автора), отмечены знаком (!)
Java 10
JEPs proposed to target JDK 10.
(!) Актуальное состояние JDK 10.
Ранние…
Стоимость: бесплатно при условии регистрацииРегистрация на ивент: aboutqa.kit.center
Семинар ориентирован на аудиторию, которая ищет…

Цього року 23 736 спеціалістів оцінили 1391 компанію. За результатами їхнього голосування ми склали рейтинг найкращих…
28 грудня у «Часописі» говоритимемо про технологічні тренди наступних 10 років з Ярославом Ажнюком і Павлом…
На днях Фонд BrainBasket презентовал программу Technology Nation, в рамках которой планирует обучить программированию…
Elasticsearch — это одна из самых популярных систем для организации поиска, основанная на библиотеке Lucene. Раньше на этом сайте публиковалась статья в которой было рассказано как установить и настроить Elasticsearch, а также как использовать основные типы запросов, фильтры и группировку данных.
В этой статье я хочу сосредоточится только на поиске. Мы рассмотрим как работают анализаторы, токенизаторы, а также разберемся как всё это эффективно использовать для организации поиска.
Для того чтобы поиск работал эффективно и был достаточно релевантным недостаточно просто сохранить заголовок текста или сам текст в поисковый индекс. Этот текст должен быть разбит на токены. Это части текста по которым будет выполнятся поиск. По умолчанию Elasticsearch использует анализатор standard для всех полей с типом text. Этот анализатор разбивает текст на слова согласно алгоритму сегментации Unicode и работает с большинством языков.
Это можно проверить на примере. У Elasticsearch есть API, которое позволяет посмотреть на какие токены будет разбит текст при использовании определённого анализатора. Давайте рассмотрим пример. В этой статье я предлагаю использовать Kibana для запросов к Elasticsearch, потому что запросы будут сложные и выполнять их в curl не удобно. Синтаксис API анализа выглядит следующим образом:
_analyze
{
«analyzer»: «название_анализатора»,
«text»: «текст для анализа»
}
Для примера давайте посмотрим каким образом будет разбито предложение «В чащах юга жил был цитрус, да но фальшивый экземпляр»:
POST _analyze
{
"analyzer" : "standard",
"text" : "В чащах юга жил был цитрус, да но фальшивый экземпляр"
}
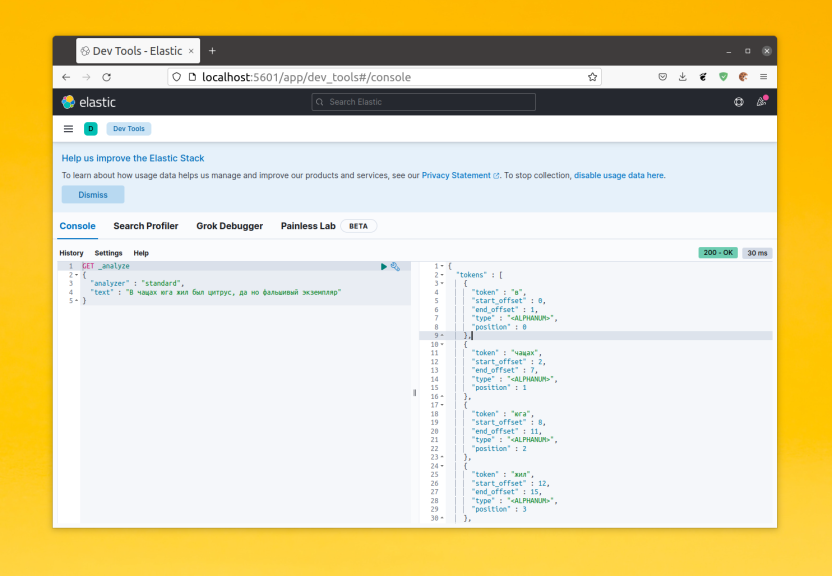
Как видите, текст разбивается на слова и если пользователь будет искать слово «чащах», то сможет найти этот документ. Такой алгоритм разбиения используется как на этапе индексирования, так и на этапе поиска. Поэтому поисковый запрос тоже будет разбит на токены и если будут совпадения то документ будет найден. Обратите внимание, что ElasticSearch использует анализатор как при индексации, так и при поисковом запросе. Конечно, на то как будут сопоставляться сами токены влияет какой тип запроса будет использован. Например: match, match_phrase, multi_match, query_string, а также будет ли включён нечёткий поиск Elasticsearch (fuzzines). Но в целом, это работает именно так. Меняя анализаторы и тип поискового запроса можно делать поиск более релевантным для вашего проекта.
Настройка поиска в ElasticSearch
Для следующих примеров давайте создадим индекс под названием test_index в котором будет два поля: title и content. Оба они будут иметь тип text и пока что будут использовать анализатор standard:
PUT test_index
{
"mappings" : {
"properties" : {
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"content" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
Затем добавьте в получившийся индекс одну запись:
POST test_index/_doc
{
"title": "В чащах юга",
"content": "жил был цитрус, да но фальшивый экземпляр"
}
Теперь можно переходить к рассмотрению возможностей поиска ElasticSearch.
1. Поисковый запрос match
Запрос match ищет только по одному полю. Синтаксис этого поискового запроса выглядит вот так:
"match": { "имя_поля": "запрос" }
Например, вы можете попробовать найти ранее созданный документ:
GET _search?index=test_index
{
"query": {
"match": {
"title": "Чащах"
}
}
}
Обратите внимание, что match ищет полное соответствие по токену между токенами, на которые был разбит запрос. Если вы напишите чащ или ч, то ничего не будет найдено. Если вы хотите чтобы в результирующем документе были найдены все токены из запроса добавьте в него параметр operator со значением and:
GET _search?index=test_index
{
"query": {
"match": {
"query": "Чащах юга",
"operator": "and"
}
}
}

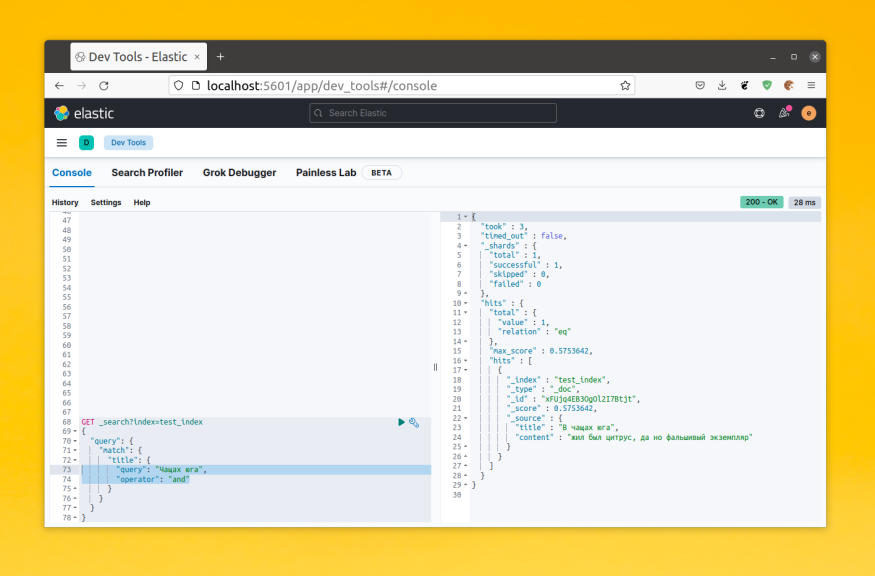
В таком виде документ будет найден, однако если вы добавите слово, которого нет в поле title, то ничего не будет найдено. Есть также поисковые запросы multi_match, match_phrase и т д. Например, если вы хотите поиск по нескольким полям Elasticsearch, используйте запрос multi_match, а если вам нужно вхождение полной фразы — используйте match_phrase.
2. Поисковый запрос query_string
Этот запрос работает похожим образом на match. Только по умолчанию он выполняет поиск по всем полям и поддерживает простые операторы в поисковом запросе, такие как AND и OR. Синтаксис query_string такой:
"query_string": { "query": "запрос" }
Например, вы можете запрос на поиск ранее созданного документа будет выглядеть вот так:
GET _search?index=test_index
{
"query": {
"query_string": {
"query": "Чащах OR юга"
}
}
}
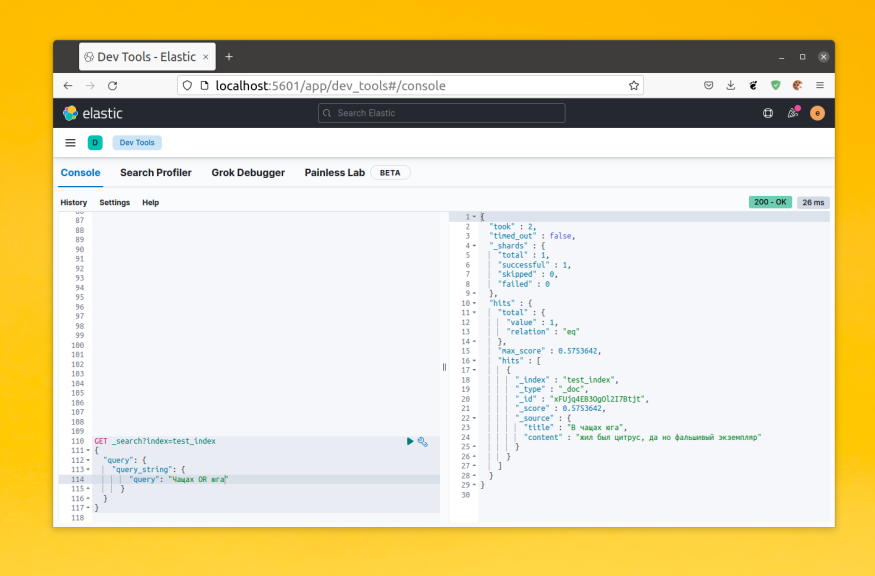
Также можно задать поле для поиска с помощью параметра default_field:
GET _search?index=test_index
{
"query": {
"query_string": {
"query": "Чащах OR юга",
"default_field": "title"
}
}
}
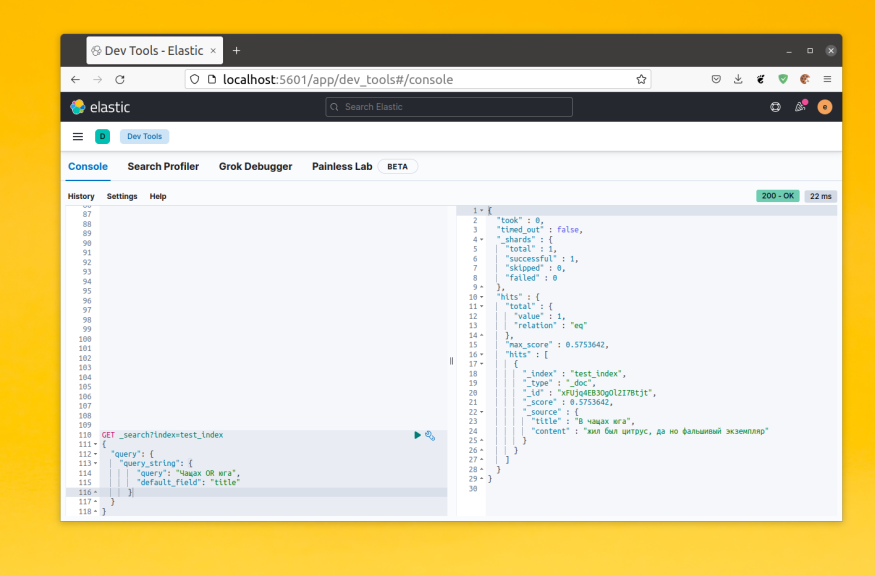
Тут можно делать довольно сложные запросы и указывать поле для поиска прямо в запросе. Однако если вы попытаетесь найти часть слова, то снова увидите что ничего не будет найдено. Такой поиск уже неплохо работает, но обычно пользователи хотят чтобы даже не полностью набранные слова дополнялись.
2. Нечеткий поиск
Кроме точного поиска, который мы рассмотрели выше, Elasticsearch поддерживает поиск неточных соответствий. Существует запрос fuzzy, а также в запрос match или query_string можно передать параметр fuzziness, который принимает максимальное расстояние между словами и включит нечеткий поиск Elasticsearch. Это всё работает на основе алгоритма расчёта расстояния Левенштейна. В этом алгоритме слова сравниваются посимвольно и если символ отличается, то расстояние увеличивается на единицу. Например, между словами чащах и кущах будет расстояние 2 потому что отличаются два символа. Таким образом, следующий запрос найдёт документ из примера:
GET _search?index=test_index
{
"query": {
"match": {
"title": {
"query": "кущах",
"operator": "and",
"fuzziness": 2
}
}
}
}
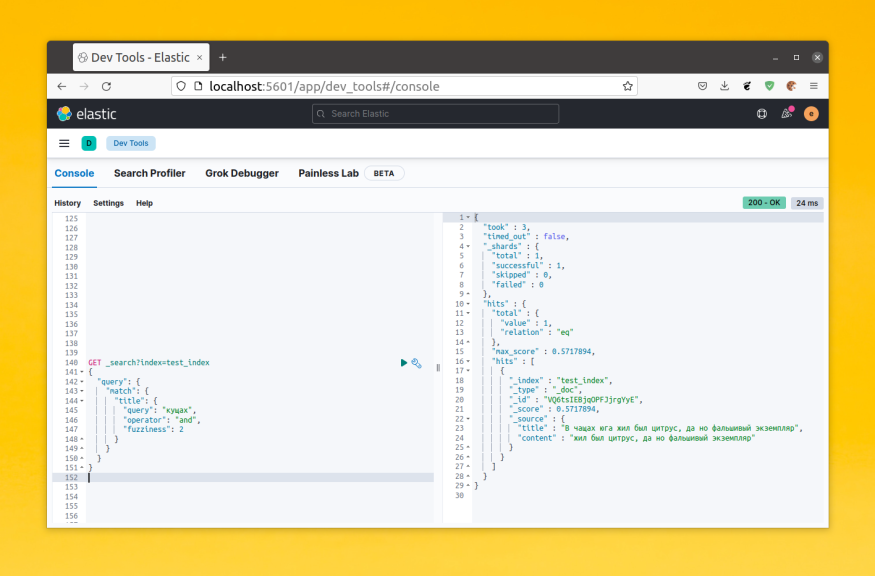
Однако, с fuzziness надо быть очень аккуратным. Она хороша для автодополнения и коррекции опечаток, но в реальном поиске она может добавить очень много не релевантных результатов в выдачу. Поэтому для улучшения поиска следует поискать другие способы. Например, менять настройки анализатора.
2. Анализатор языка
Вы можете улучшить поиск применив вместо стандартного анализатора анализатор языка, на котором выполняется поиск. У ElasticSearch есть анализаторы для множества языков, в том числе и для русского. Анализатор для русского языка разбивает предложение на токены и вместо слов старается сохранить их корневую форму:
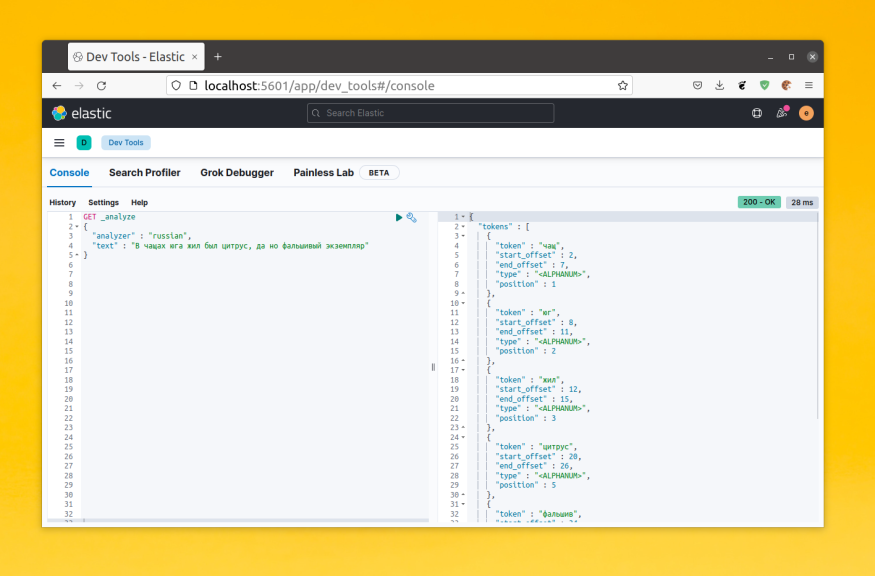
Для того чтобы изменить анализатор для поля надо пересоздать индекс. Сначала удалите старый индекс:
DELETE test_index
Рядом с типом поля достаточно указать анализатор с помощью параметра analyzer. Этот параметр задает анализатор для индексации. Желательно также задать анализатор для поискового запроса с помощью параметра search_analyzer, который бы работал подобным образом. Например:
PUT test_index
{
"mappings" : {
"properties" : {
"title" : {
"type" : "text",
"analyzer": "russian",
"search_analyzer": "russian",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"content" : {
"type" : "text",
"analyzer": "russian",
"search_analyzer": "russian",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
Снова добавьте в индекс ту же запись и попробуйте искать её:
GET _search?index=test_index {
"query": {
"match": {
"title": "Чащ"
}
}
}
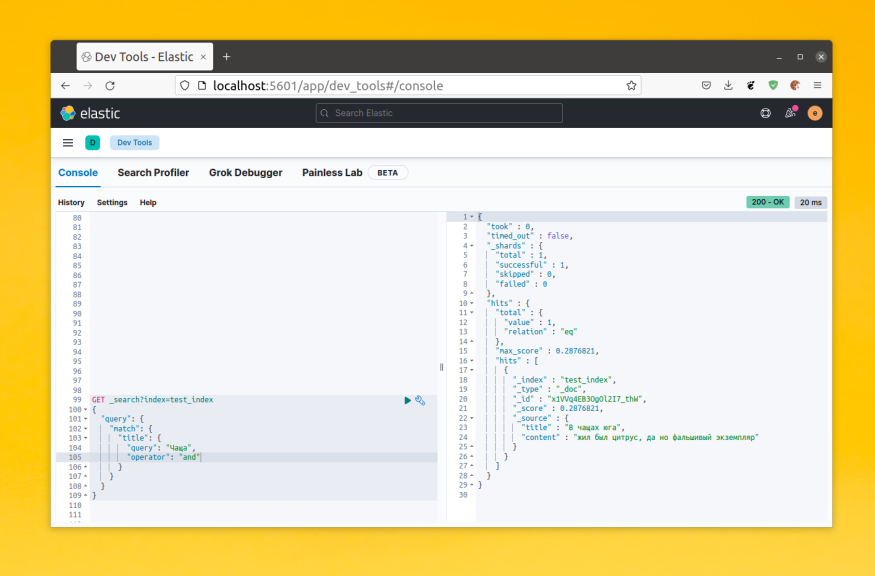
Как видите, теперь это работает лучше. Вы можете написать часть слова, слово в других формах и документ будет найден. Однако это подходит не для всех случаев. Если у вам нужно искать по сложным названиям, которых нет в словаре и которые состоят из букв, цифр и других символов, то это не будет работать так хорошо. Вы можете создать свой анализатор, который будет разбивать текст на нужные токены и применять к ним нужные изменения.
3. Создание своего анализатора
Для создания своего анализатора надо добавить раздел settings при создании индекса, а в него добавить раздел analysis. Сам анализатор составляется из настроек действий, которые будут применены к анализируемому тексту. Вот они:
- type — можно унаследовать свой анализатор от других, уже существующих анализаторов или же использовать тип custom для создания пустого анализатора.
- tokenizer — свой или стандартный токенизатор, который будет разбивать текст на токены.
- filter — список фильтров, которые будут применены к токенам.
Давайте для примера создадим простой анализатор. В качестве токенизатора будет использоваться whitespace, который разбивает текст на слова по пробелам, а в качестве фильтра будет применяться lovercase, который приводит запрос к нижнему регистру. Анализатор standard делает это автоматически, но в своём анализаторе надо это делать с помощью фильтра:
PUT test_index
{
"settings": {
"analysis": {
"analyzer": {
"custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"lowercase",
]
}
}
}
},
"mappings" : {
"properties" : {
"title" : {
"type" : "text",
"analyzer": "custom_analyzer",
"search_analyzer": "custom_analyzer",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"content" : {
"type" : "text",
"analyzer": "custom_analyzer",
"search_analyzer": "custom_analyzer",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
Вы можете снова добавить запись в индекс и проверить как это работает. Дальше давайте рассмотрим как добавить свой токенизатор для анализатора.
4. Выбор токенизатора
Большинство токенизаторов просто делят текст на слова, подобно тому как это делается в анализаторе standard, но учитывая разные условия. Вот основные из них:
- starnard — разбивает текст на слова;
- letter — разбивает текст на буквы;
- whitespace — разбивает текст на токены по пробелам;
- ngram — разбивает текст на n-грамы;
- edge_ngram — разбивает текст сначала на слова, а потом на n-грамы от начала слова;
- pattern — позволяет использовать регулярное выражение для определения разделителя;
- path — разбивает путь к файлу на эелементы пути, по слешу.
Самые интересные токенизаторы, это ngram и enge_ngram. Они позволяют разбивать текст на n-граммы, последовательности из определённого количества букв. Оба разбивают текст сначала на слова, а затем эти слова на n-граммы. Но первый создает n-граммы только от начала каждого слова, а второй для всех букв слова. Это довольно удобно, потому что позволяет пользователям вводить для поиска не слово целиком, а только его часть.
5. Настройка токенизатора edge_ngram
Такой токенизатор очень часто используется для автоматического дополнения ввода пользователя и для быстрых подсказок, подобных тем, что показываются при вводе поискового запроса в Google. Вот основные параметры токенизатора edge_ngram, которые нужно задать:
- min_gram — минимальный размер n-граммы;
- max_gram — максимальный размер n-граммы;
- token_chars — символы из которых состоят слова, необходимо для того чтобы текст корректно разбивался на слова, а уже сами слова на n-граммы. Доступны значения: letter, digit, punctuation, symbol, whitespace.
Давайте посмотрим как работает токенизатор edge_ngram:
GET _analyze
{
"tokenizer" : {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20,
"token_chars": [
"letter",
"digit"
]
},
"text" : "В чащах юга жил был цитрус, да но фальшивый экземпляр"
}
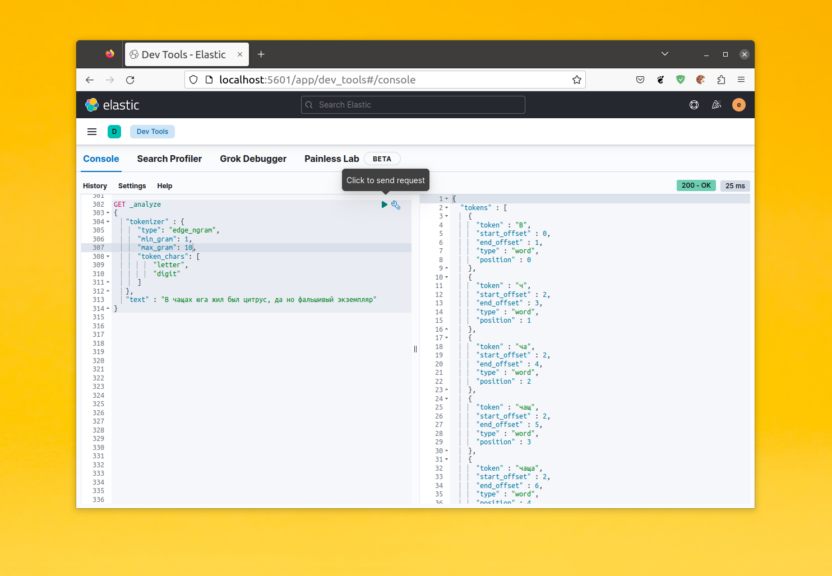
Как видите, слова разбиваются на n-граммы от начала слова, например: ч, ча, чащ, чаща, чащах. Таким образом если пользователь начнет вводить слово в поиск, то ElasticSearch сможет догадаться что он хочет найти. Кроме того, если вы хотите чтобы в ваши слова входили другие символы, можно добавить в массив token_chars тип custom и в поле custom_token_chars прописать нужные символы. Например:
GET _analyze
{
"tokenizer" : {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20,
"token_chars": [
"letter",
"digit",
"custom"
],
"custom_token_chars": ".,-_"
},
"text" : "В. чащах_юга- жил был цитрус, да но фальшивый экземпляр"
}
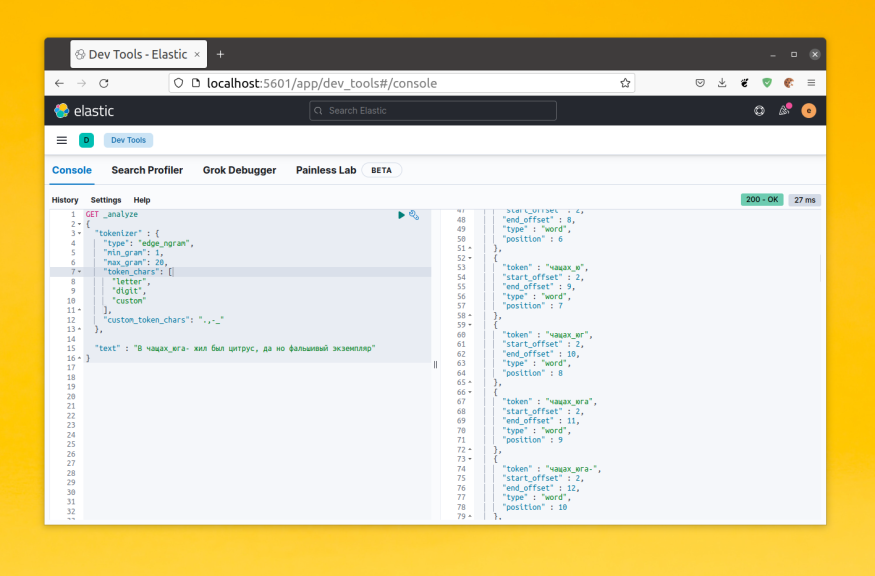
Теперь эти символы находятся в токенах и могут использоваться в поиске. Для того чтобы добавить такой токенизатор в свой анализатор в секции settings -> analysis необходимо создать объект tokenizer и там описать настройки нового токенизатора, после чего добавить его в анализатор. Например:
PUT test_index
{
"settings": {
"analysis": {
"tokenizer": {
"ngram_tokenizer": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20,
"token_chars": [
"letter",
"digit",
"custom"
],
"custom_token_chars": ".,-_"
}
},
"analyzer": {
"custom_analyzer": {
"type": "custom",
"tokenizer": "ngram_tokenizer",
"filter": [
"lowercase"
]
}
}
}
},
"mappings" : {
"properties" : {
"title" : {
"type" : "text",
"analyzer": "custom_analyzer",
"search_analyzer": "custom_analyzer",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"content" : {
"type" : "text",
"analyzer": "custom_analyzer",
"search_analyzer": "custom_analyzer",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
Теперь при поиске можно использовать части слова, например: ч, ча, чащ, чаща. И всё это будет работать. Кроме, того если в слове содержатся символы из ранее заданного списка, то оно тоже будет находится. Например:
GET _search?index=test_index
{
"query": {
"match": {
"title": {
"query": "чащах_юга-",
"operator": "and"
}
}
}
}
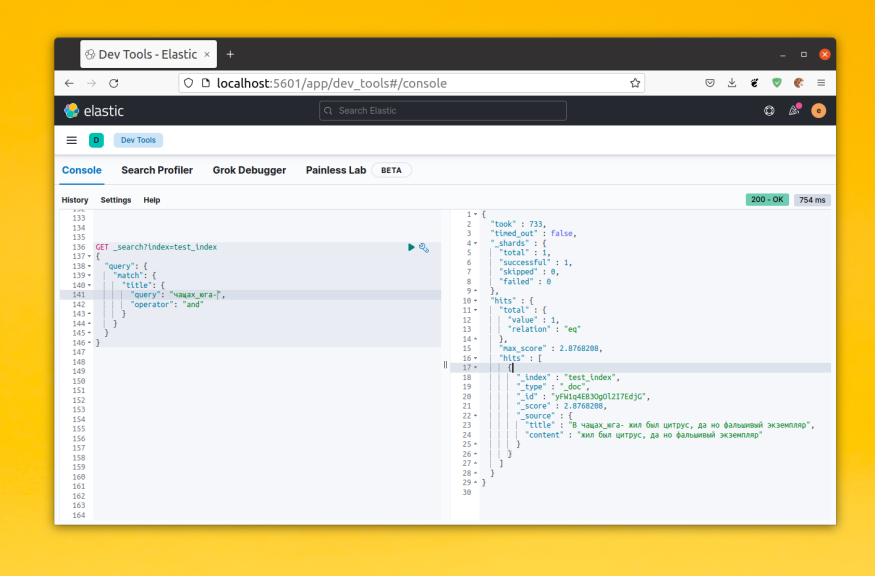
6. Настройка токенизатора ngram
Предыдущий токенизатор довольно интересный, но он имеет свои ограничения. Поисковый запрос должен начинаться обязательно с начала слова в тексте. Если пользователь введет несколько символов из середины слова, то ElasticSearch ничего не найдёт. Если это не желательное поведение, то лучше использовать токенизатор ngram. Он разбивает весь текст на n-граммы независимо от слов.
Параметры тут те же что и у edge_ngram, но, по умолчанию параметр max_ngram может быть больше за min_ngram на единицу. Это не всегда подходит. Для того чтобы это исправить можно воспользоваться настройкой max_ngram_diff на уровне индекса:
PUT another_index
{
"settings": {
"max_ngram_diff": 20
}
}
GET another_index/_analyze
{
"tokenizer" : {
"type": "ngram",
"min_gram": 1,
"max_gram": 10,
"token_chars": [
"letter",
"digit"
]
},
"text" : "В чащах юга жил был цитрус, да но фальшивый экземпляр"
}
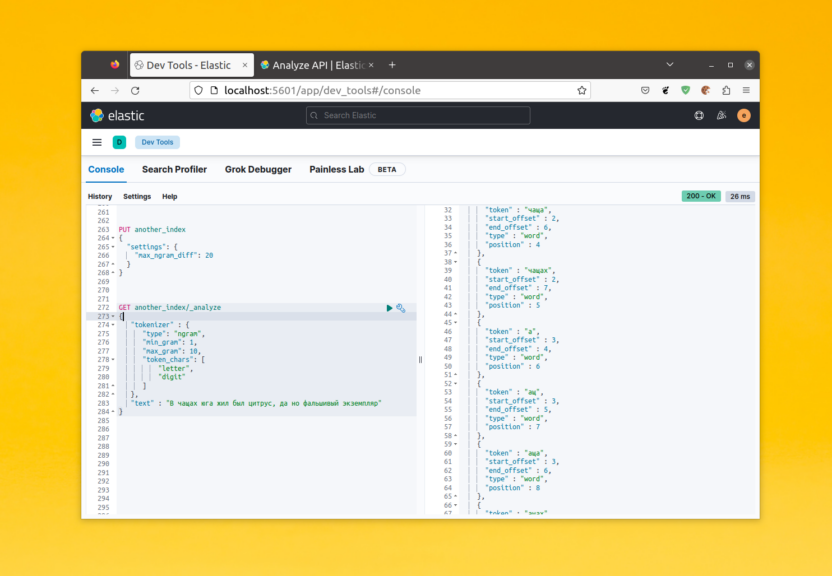
7. Настройка фильтров
Как вы уже видели, с помощью фильтров можно изменять токены. Например, приводить их к нижнему регистру, удалять стоп слова или символы. Если фильтр не требует настройки можно добавить его прямо в анализатор. Если же в фильтре нужно задать определённые параметры, его нужно настраивать также как и токенизатор. Для этого в секции settings -> analysis создайте объект фильтр, и там опишите нужный фильтр. Например, можно добавить поддержку морфологии русского языка в свой анализатор с помощью фильтра stemmer. Это будет выглядеть вот так:
"settings": {
"analysis": {
"filter": {
"russian_stemmer": {
"type": "stemmer",
"language": "russian"
}
}
.......
}
}
Дальше этот фильтр можно добавить в массив фильтров анализатора. Вы можете посмотреть как будет работать фильтр с помощью API анализа:
GET _analyze
{
"tokenizer" : {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20,
"token_chars": [
"letter",
"digit",
"custom"
],
"custom_token_chars": ".,-_"
},
"filter": {
"type": "stemmer",
"language": "russian"
},
"text" : "В чащах_юга- жил был цитрус, да но фальшивый экземпляр"
}
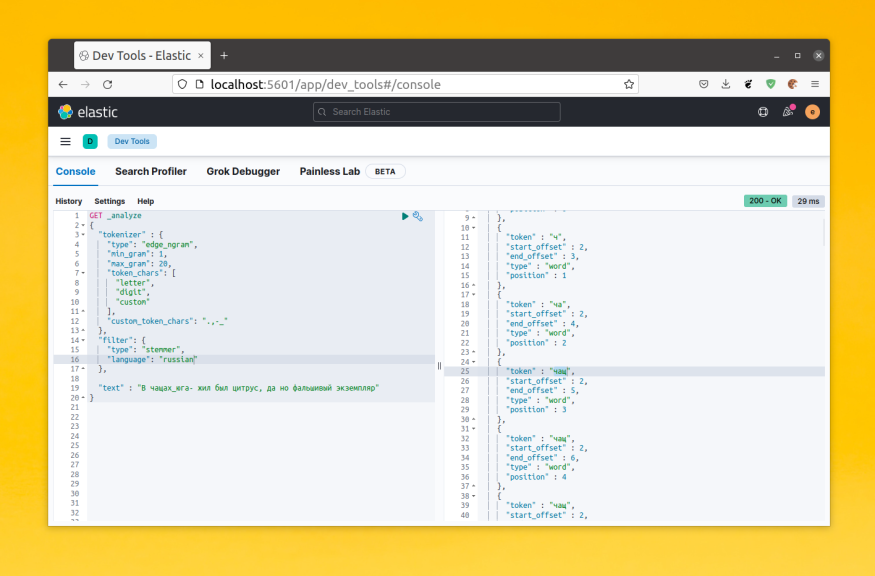
Как видите, здесь все слова, которые были в словаре стиммера были приведены к корневой форме и теперь пользователи будут находить больше релевантных результатов.
8. Синонимы
Часто в поиске возникает необходимость задать синонимы для определённых слов. В ElasticSearch синонимы можно задать на этапе создания индекса с помощью фильтров токенов. Для этого используется фильтр synonym или synonym_graph. Первый работает для обычных синонимов. Для синонимов, которые состоят из нескольких слов надо использовать synonym_graph, но его можно применить только в анализаторе поиска. Давайте рассмотрим пример использования synonym_graph. Синтаксис настройки фильтра выглядит так:
"filter": {
"synonym": {
"type": "synonym_graph",
"synonyms": [ "синоним_1, синоним_2, синоним_3" ]
}
}
Для примера давайте создадим анализатор, который будет использоваться только на этапе поиска и будет поддерживать синонимы для слова чаща:
PUT test_index
{
"settings": {
"analysis": {
"filter": {
"synonym_filter": {
"type": "synonym_graph",
"synonyms": [
"чащах, зарослях, гуще, дебрях, куще"
]
}
},
"tokenizer": {
"ngram_tokenizer": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20,
"token_chars": [
"letter",
"digit",
"custom"
],
"custom_token_chars": ".,-_"
}
},
"analyzer": {
"custom_analyzer": {
"type": "custom",
"tokenizer": "ngram_tokenizer",
"filter": [
"lowercase"
]
},
"custom_search_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"synonym_filter"
]
}
}
}
},
"mappings" : {
"properties" : {
"title" : {
"type" : "text",
"analyzer": "custom_analyzer",
"search_analyzer": "custom_search_analyzer",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"content" : {
"type" : "text",
"analyzer": "custom_analyzer",
"search_analyzer": "custom_search_analyzer",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
После того как вы создадите этот индекс, можно проверить как работает его анализатор с фильтром синоноимов:
GET test_index/_analyze
{
"analyzer": "custom_search_analyzer",
"text": "В чащах югра жил был цитрус, да но фальшивый экземпляр"
}
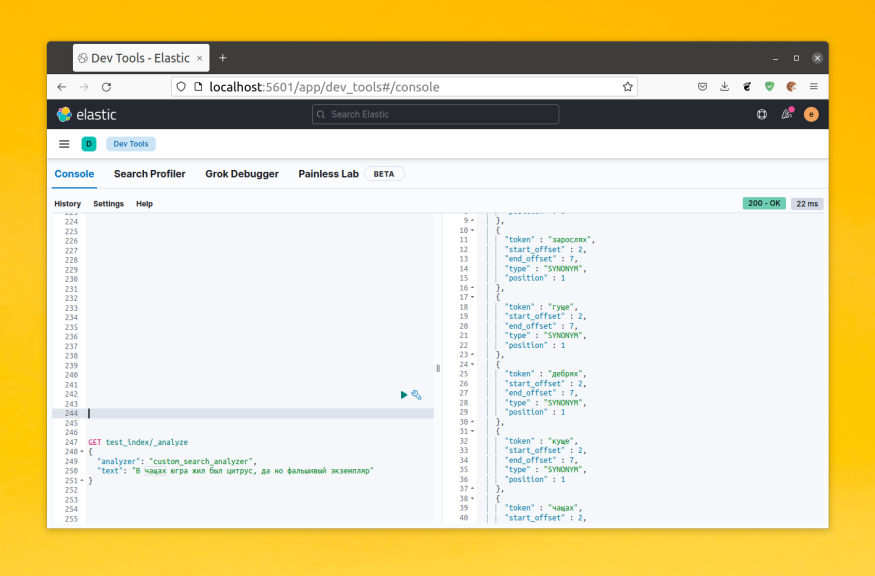
Как видите, теперь для слова, у которого есть синонимы, создаются токены всех синонимов и при поиске в индексе такие слова будут находится по синонимам.
Выводы
В этой статье мы рассмотрели как использовать Elasticsearch для поиска. Если его правильно настроить, то получится довольно мощный поисковый движок, который будет выдавать релевантные результаты для вашего проекта. Как видите, тут есть довольно много интересного и в статье были рассмотрены только основы. Чтобы разобраться во всём более подробно вам нужно обратиться к официальной документации.
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.

Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .

This repository contains a curated dataset of synonyms in Solr Format. These
synonyms can be used for Elasticsearch Synonym Token Filter configuration.
Additional helper tools in this repository:
synlint: Commandline tool to lint and validate the synonym files.synonyms.sublime-syntax: Syntax highlighting file for Sublime Text 3.
If you’re using Elasticssearch with Django, you might find dj-elasticsearch-flex useful.
Why?
Trying to configure Synonyms in Elasticsearch, I found that docs for it are surprisingly scattered.
The docs that are available do not do much justice either and miss out many corner cases.
For instance, an incorrect Solr mapping: hello, world, would be happily added in index configuration.
However, as soon as you’d try to re-open the index, you’d get a malform_input_exception (discussion thread).
This repository solves such problems by with a linter tool that can be used to validate the synonym
files beforehand.
Datasets
The synonym files in data/ can be used directly in elasticsearch configuration.
Following datasets are currently available:
be-ae: British English and American English Spellings. From AVKO.org.medical-terms: A Synonym file with several Medical terminologies, abbreviations and resolution.
Installation
If you want to use the synlint tool, install the package from PIP using:
pip install elasticsearch-synonym-toolkit
The Python Package is installed as es_synonyms. This will also install a linter tool,
es-synlint. Use it with:
Usage
In most cases, you’d want to use this module as a helper for loading validated synonyms from a file or a url:
from es_synonyms import load_synonyms # Load synonym file at some URL: be_ae_syns = load_synonyms('https://to.noop.pw/2sI9x4s') # Or, from filesystem: other_syns = load_synonyms('data/be-ae.synonyms')
Configuring Synonym Tokenfilter with Elasticsearch DSL Py, is very easy, too:
from elasticsearch_dsl import analyzer, token_filter be_ae_syns = load_synonyms('https://to.noop.pw/2sI9x4s') # Create a tokenfilter brit_spelling_tokenfilter = token_filter( 'my_tokenfilter', # Any name for the filter 'synonym', # Synonym filter type synonyms=be_ae_syns # Synonyms mapping will be inlined ) # Create analyzer brit_english_analyzer = analyzer( 'my_analyzer', tokenizer='standard', filter=[ 'lowercase', brit_spelling_tokenfilter ])
To use the underlying linter, you can import SynLint class.
Development
- Clone this repository.
- Install package dependencies via
pipwith:pip install -r requirements.txt. - To run tests:
License
The tools and codes are licensed under MIT.
The datasets are used under fair use and are derivative of the original sources.
This repository contains a curated dataset of synonyms in Solr Format. These
synonyms can be used for Elasticsearch Synonym Token Filter configuration.
Additional helper tools in this repository:
synlint: Commandline tool to lint and validate the synonym files.synonyms.sublime-syntax: Syntax highlighting file for Sublime Text 3.
If you’re using Elasticssearch with Django, you might find dj-elasticsearch-flex useful.
Why?
Trying to configure Synonyms in Elasticsearch, I found that docs for it are surprisingly scattered.
The docs that are available do not do much justice either and miss out many corner cases.
For instance, an incorrect Solr mapping: hello, world, would be happily added in index configuration.
However, as soon as you’d try to re-open the index, you’d get a malform_input_exception (discussion thread).
This repository solves such problems by with a linter tool that can be used to validate the synonym
files beforehand.
Datasets
The synonym files in data/ can be used directly in elasticsearch configuration.
Following datasets are currently available:
be-ae: British English and American English Spellings. From AVKO.org.medical-terms: A Synonym file with several Medical terminologies, abbreviations and resolution.
Installation
If you want to use the synlint tool, install the package from PIP using:
pip install elasticsearch-synonym-toolkit
The Python Package is installed as es_synonyms. This will also install a linter tool,
es-synlint. Use it with:
Usage
In most cases, you’d want to use this module as a helper for loading validated synonyms from a file or a url:
from es_synonyms import load_synonyms # Load synonym file at some URL: be_ae_syns = load_synonyms('https://to.noop.pw/2sI9x4s') # Or, from filesystem: other_syns = load_synonyms('data/be-ae.synonyms')
Configuring Synonym Tokenfilter with Elasticsearch DSL Py, is very easy, too:
from elasticsearch_dsl import analyzer, token_filter be_ae_syns = load_synonyms('https://to.noop.pw/2sI9x4s') # Create a tokenfilter brit_spelling_tokenfilter = token_filter( 'my_tokenfilter', # Any name for the filter 'synonym', # Synonym filter type synonyms=be_ae_syns # Synonyms mapping will be inlined ) # Create analyzer brit_english_analyzer = analyzer( 'my_analyzer', tokenizer='standard', filter=[ 'lowercase', brit_spelling_tokenfilter ])
To use the underlying linter, you can import SynLint class.
Development
- Clone this repository.
- Install package dependencies via
pipwith:pip install -r requirements.txt. - To run tests:
License
The tools and codes are licensed under MIT.
The datasets are used under fair use and are derivative of the original sources.