Датасет: ассоциации к словам и выражениям русского языка
Время на прочтение
3 мин
Количество просмотров 13K
В последнее время для оценки семантического сходства широкое распространение получили методы дистрибутивной семантики. Эти подходы хорошо показали себя в ряде практических задач, но они имеют ряд жёстких ограничений. Так, например, языковые контексты оказываются сильно схожими для эмоционально полярных слов. Следовательно, антонимы с точки зрения word2vec часто оказываются близкими словами. Также word2vec принципиально симметричен, ведь за основу берётся совстречаемость слов в тексте, а популярная мера сходства между векторами — косинусное расстояние — также не зависит от порядка операндов.
Мы хотим поделиться с сообществом собранной нами базой ассоциаций к словам и выражениям русского языка. Этот набор данных лишён недостатков методов дистрибутивной семантики. Ассоциации хорошо сохраняют эмоциональную полярность и они по своей природе асимметричны. Подробнее расскажем в статье.
Почему дистрибутивная семантика «не видит» часть картины мира?
Письменный язык — это очень сильно сжатая информация. Чтобы распаковать её и понять суть мы подключаем дополнительные ресурсы — здравый смысл, наши знания о мире, культурный контекст. Если часть такой информации вам недоступна, например вы попали в новую компанию или погружаетесь в новую предметную область, вы будете вынуждены восполнять пробелы в знаниях, задавая вопросы или изучая дополнительные источники.
Компьютер лишён (пока) такой возможности учиться. Поэтому NLP-разработчику важно понимать, что части полезной информации о мире в тексте нет и быть не может. Её нужно собирать и подключать дополнительно.
Что такое ассоциации?
Все в детстве играли в игру, когда один человек называет слово, сосед предлагает свою ассоциацию. Потом придумается ассоциация к ассоциации и т.д. Часто интересно не только услышать ассоциацию другого человека, но и понять ход его мыслей, как он пришёл к тому или иному слову. Это позволяет немного заглянуть в то, как мы мыслим.
Можно посмотреть на это и по-другому. Живые люди обладают наиболее актуальной и несжатой информацией о мире и о языке. С этим связана наша изумительная способность разрешать языковые неоднозначности. Любая модель языка будет срезом этой информации с неизбежными потерями. Дистрибутивные модели дают один срез, ассоциации позволяют взглянуть под другим углом. Возможно путь к чуть более объёмной языковой картинке лежит в использовании обеих моделей.
TL;DR или дайте ссылку на датасет
Собственно датасет, которым мы хотим поделиться с сообществом, представляет собой базу таких ассоциаций. Ниже мы расскажем об особенностях данных, но если вам не терпится — смело листайте вниз и переходите на Гитхаб, чтобы скачать базу.
Несимметричность матрицы ассоциаций
Ещё одной досадной особенностью дистрибутивных моделей является их симметричность. Т.е. СТУЛ и МЕБЕЛЬ окажутся похожими, но как понять отношение слов друг к другу? Немного помогает кластеризация поверх векторов, но в исходной модели этой информации нет.
Ассоциации несимметричны. Так, например, к слову ЛАЙМ будет сильная ассоциация ФРУКТ. Но обратное неверно — ЛАЙМ если и ассоциируется со словом ФРУКТ, то далеко не в первую очередь. Это связано как с обобщающей ролью слова ФРУКТ в языке, так и с актуальным культурным контекстом жителей России.
Соответственно зеркальность и её количественное выражение являются интересными атрибутами ассоциаций, выгодно отличающих их от чисто статистических инструментов, таких как дистрибутивные модели.
Что можно сделать с датасетом
Мы видим конечную цель всех исследований языка в том, чтобы научить компьютер понимать язык на уровне человека. Это не обязательно предполагает умение машины мыслить (что бы мы не вкладывали в это понятие), достаточно умело эмулировать то, как человек работает с языком.
Хочется надеяться, что дополнительные источники информации, которых для русского не так много, помогут учёным и исследователям продвинуться на этом пути. Ниже мы предложим несколько направлений исследований, которые показались нам достаточно интересными:
- Реализовать алгоритм assoc2vec, взяв за основу идеи из GloVe и заменив контекстную совстречаемость ассоциативной.
- Кластеризовать ассоциации в рамках каждого отдельного головного слова или датасета в целом, например чтобы выделить кластера отдельных значений слова.
- Исследовать возможность автоматического построения тезауруса русского языка. (Наблюдение: в отличие от контекстов матрица ассоциаций асимметрична.)
- Использовать срезы ассоциаций по гендеру для проведения социологического исследования.
- Сделать интересную визуализацию самих ассоциаций и связей внутри датасета. (Например карту всевозможных путей между ассоциациями.)
- Исследовать природу симметричности/асимметричности относительных частот зеркальных ассоциаций.
Это лишь несколько идей, в реальности их может быть гораздо больше. Придумывайте свои эксперименты и обязательно делитесь результатами на Хабре или даже в научных журналах.
Ссылка на скачивание и лицензия
Датасет: ассоциации к словам и выражениям русского языка
Датасет распространяется по лицензии CC BY-NC-SA 4.0.

Python-библиотека NLPAug позволяет устранить дисбаланс между классами данных в текстовых датасетах путем замены слов на синонимы, двойного перевода и других методов. Использование библиотеки повышает эффективность нейросетей, оперирующих с текстами, без необходимости изменения архитектуры модели и ее тонкой настройки.
Содержание датасета, используемого для обучения нейросети — один из ключевых фактором, определяющих ее эффективность. Наиболее распространенными проблемами датасетов, приводящими к невозможности построить надежную модель машинного обучения, являются недостаточное количество данных и дисбаланс различных групп данных, представленных в датасете. Аугментация данных — это синтез новых данных из уже имеющихся данных. Аугментация может применяться к любому типу данных — от чисел до изображений. Например, чтобы увеличить количество изображений, можно деформировать (вращать, обрезать и т. д.) имеющиеся фотографии. Гораздо более сложной задачей является аугментация текстовых данных. Например, изменение порядка слов на первый взгляд может показаться может полностью изменить смысл предложения.
Библиотека NLPAug предоставляет эффективные инструменты для быстрой аугментации текстов:
- замена определенного количества слов их синонимами;
- замена определенного количества слов словами, которые имеют аналогичные (основанные на косинусном сходстве) векторные представления (такие как word2vec или GloVe);
- замена слов на основе контекста с использованием трансформеров (например, BERT);
- двойной перевод, то есть перевод текста на другой язык и обратно, в ходе которого происходит замена нескольких слов.
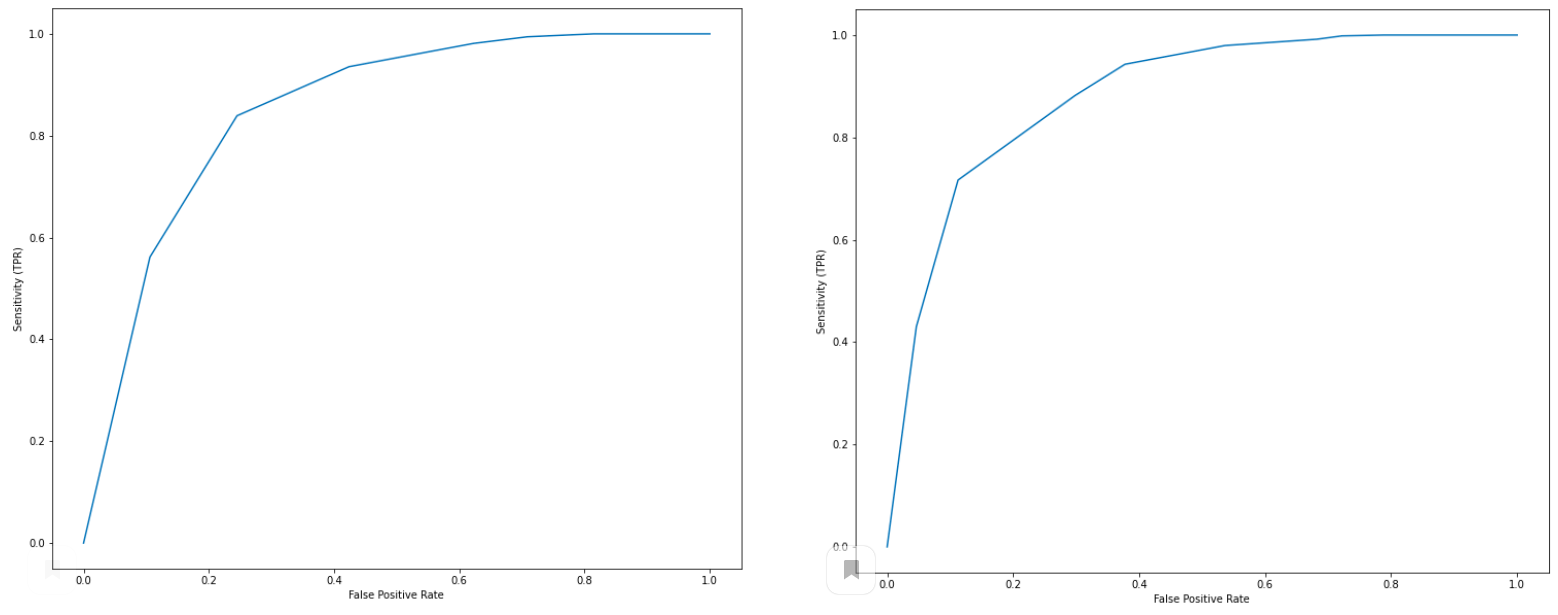
NLPAug дает возможность увеличения эффективности моделей (например, в терминах ROC-кривых) без изменения архитектуры и тонкой настройки нейросетей. В качестве примера можно рассмотреть датасет, состоящий из 7000 отзывов Yelp на кофейни, для которого выполняется анализ тональности текстов и сравнение с оценками кофеен по 5-балльной шкале, выставленными авторами отзывов. Исходно датасет сильно несбалансирован: количество положительных отзывов в 6.5 раз превышает количество отрицательных. В примере выполняется аугментация отрицательных отзывов: из каждого такого отзыва генерируется два новых, в которых максимум 3 слова меняются на синонимы. Выполнение этой операции занимает менее 1 минуты на CPU, требует менее 5 строк кода и приводит к увеличению показателя AUC с 0,85 до 0,88:
Содержание
- 1 Русский
- 1.1 Морфологические и синтаксические свойства
- 1.2 Произношение
- 1.3 Семантические свойства
- 1.3.1 Значение
- 1.3.2 Синонимы
- 1.3.3 Антонимы
- 1.3.4 Гиперонимы
- 1.3.5 Гипонимы
- 1.4 Родственные слова
- 1.5 Этимология
- 1.6 Фразеологизмы и устойчивые сочетания
- 1.7 Перевод
- 1.8 Библиография
Русский[править]
| В Викиданных есть лексема датасет (L103480). |
Морфологические и синтаксические свойства[править]
| падеж | ед. ч. | мн. ч. |
|---|---|---|
| Им. | датасе́т | датасе́ты |
| Р. | датасе́та | датасе́тов |
| Д. | датасе́ту | датасе́там |
| В. | датасе́т | датасе́ты |
| Тв. | датасе́том | датасе́тами |
| Пр. | датасе́те | датасе́тах |
да—та—се́т
Существительное, неодушевлённое, мужской род, 2-е склонение (тип склонения 1a по классификации А. А. Зализняка).
Корень: -датасет-.
Произношение[править]
- МФА: [dətɐˈsɛt]
Семантические свойства[править]
Значение[править]
- информ. в файловой системе мейнфреймов от ‘IBM — коллекция из логических записей, хранящихся в виде кортежа ◆ Отсутствует пример употребления (см. рекомендации).
- прогр. логически неделимый набор данных ◆ Отсутствует пример употребления (см. рекомендации).
Синонимы[править]
Антонимы[править]
Гиперонимы[править]
Гипонимы[править]
Родственные слова[править]
| Ближайшее родство | |
Этимология[править]
От англ. dataset.
Фразеологизмы и устойчивые сочетания[править]
Перевод[править]
| Список переводов | |
Библиография[править]
|
|
Для улучшения этой статьи желательно:
|
Анализ данных • 15 августа 2022 • 5 мин чтения
Для чего аналитику данных датасет и где его взять
Работа аналитика — находить закономерности в данных. С неопределёнными и неструктурированными данными делать это невозможно — они не подчиняются инструментам анализа и не позволяют обучать нейросети. Поэтому для работы аналитикам нужны уже подготовленные однозначные данные — датасеты.
- Что такое датасет для анализа данных
- Из чего состоит датасет
- Виды датасетов
- Где искать датасеты
- Совет от эксперта
Что такое датасет для анализа данных
Датасет (англ. dataset) — это обработанный и структурированный массив данных. В нём у каждого объекта есть конкретные свойства: признаки, связи между объектами или определённое место в выборке данных. Его используют, чтобы строить на основе данных гипотезы, делать выводы или обучать нейросети.
Для примера возьмём набор фотографий разных животных. Сам по себе этот набор — просто массив данных, его невозможно использовать для аналитики или обучения нейросети. Чтобы он стал датасетом, в нём должно быть однозначно прописано, какое конкретно животное изображено на фотографии и по каким признакам оно отличается от других животных.

Примитивно датасет можно представить в виде группировки по признакам
Данные в датасете могут быть разные, например:
● статистика покупок в магазине;
● географическое расположение офисов;
● демографические признаки населения;
● соответствие звуков аудиотексту;
● заболевания с конкретными симптомами.
Данных в датасете должно быть достаточно много, особенно если для анализа используется несколько признаков. Если нейросети нужно отличать кошек от собак, попугаев, лошадей и рыб, то сотни объектов для датасета не хватит. Понадобятся десятки и сотни тысяч фотографий. Если нужно спрогнозировать, что именно купит конкретный клиент, то понадобятся данные о демографии и покупках десятков тысяч других клиентов. Только так прогноз будет точным.
Два способа сбора датасета
● Вручную. Люди лично, без всякой автоматизации отсматривают объекты и описывают их признаки. Так создают обучающие датасеты из данных, которые изначально не структурированы. Например, именно так создают датасеты для распознавания изображений — люди смотрят фото и пишут, что конкретно на них изображено.
● Автоматически. Системы сбора информации сразу заполняют заранее подготовленную таблицу структурированными данными. Например, так можно собрать датасет о демографии клиентов магазина на основе анкеты, которую они заполняют на сайте.
На курсе Практикума «Аналитик данных» студенты учатся работать с датасетами: проверять их, анализировать и использовать в моделях машинного обучения.
Повышайте прибыль компании с помощью данных
Научитесь анализировать большие данные, строить гипотезы и соберите 13 проектов в портфолио за 6 месяцев, а не 1,5 года. Сделайте первый шаг к новой профессии в бесплатной вводной части курса «Аналитик данных».

Из чего состоит датасет
Датасет состоит из двух основных компонентов:
● Объект: фото, фрагмент аудио, покупатель, заболевание, название офиса.
● Характеристики объекта: конкретные признаки, связи с другими объектами, его местоположение.
Характеристики объекта обычно задают не словами, а цифрами. Например, нужно отметить пол покупателя. Это делают не буквами «М» и «Ж», а создают два признака «Мужской» и «Женский», и один могут обозначить как 0, а другой как 1.
Именно поэтому признаки часто могут иметь нулевые значения, и иногда их даже больше, чем единичных. Например, у нас есть человек и 100 вариантов городов, где он родился. Только в одном городе может стоять единица — а во всех остальных будут нули. Получается, что большая часть датасета часто пустая, и это нормально.
Чем больше в датасете для обучения объектов, тем лучше он отражает реальность, и тем более достоверной получается аналитика и обученные с её помощью нейросети.
Чем больше в датасете характеристик, тем он сложнее для анализа. Это даже называют «проклятием размерности». С ростом количества признаков сложность обработки датасета растёт не линейно, а по экспоненте, то есть очень быстро.
Для чего строят и обучают нейросети в IT

Виды датасетов
1. Простая запись
Это таблица, в строках которой расположены объекты, а в колонках — признаки. Явных связей между строками и столбцами нет, признаки просто соответствуют конкретным объектам. Чаще всего датасеты выглядят именно так.
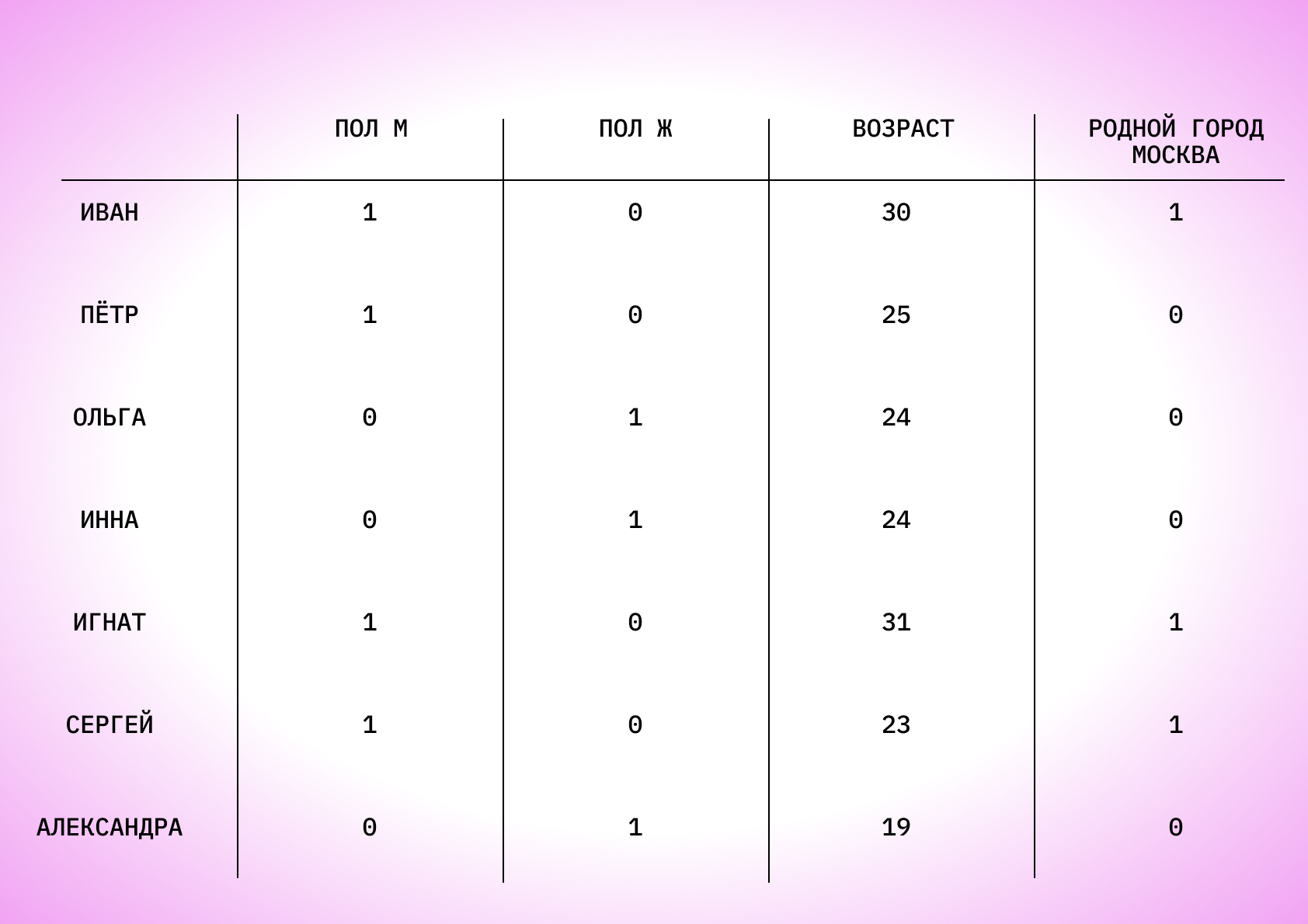
Так может выглядеть фрагмент датасета в формате простой записи
2. Граф
Данные о связях между объектами, которые могут быть представлены визуально в виде схемы из объектов, соединённых стрелками. А могут быть в виде таблицы, где в строках и колонках указаны объекты, а в пересечениях — связи между ними.
Графы бывают структурированные и неструктурированные. У первых присутствуют либо отсутствуют соотношения между объектами. У вторых они могут быть направленные — например, первый объект соотносится со вторым, а второй с первым уже нет. Кроме того, у соотношений может быть разный вес. Например, первый объект отправил второму 10 сообщений — тогда вес этого соотношения равен 10.
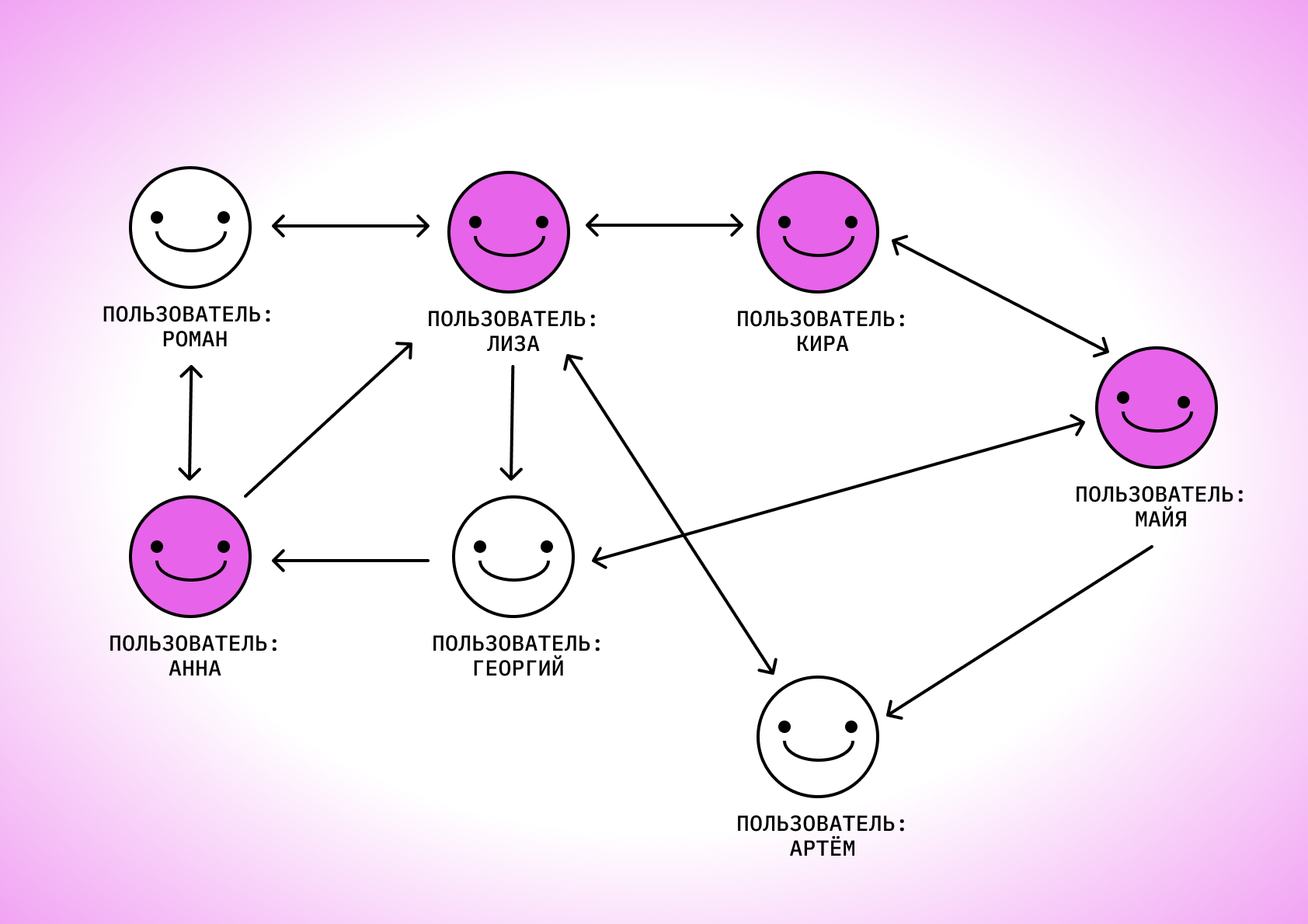
Структурированный граф пользователей социальной сети в виде визуальной схемы
3. Упорядоченные записи
Здесь роль играет не соотношение объектов или их признаки, а конкретное расположение в таблице с данными, пространстве или времени.
Например, такой датасет для анализа данных может быть в виде таблицы, в которой главная информация — это расположение объекта.

Пример такого датасета — геном, где важно расположение каждого конкретного гена
Где искать датасеты
Датасет можно собрать самостоятельно, но это дорого, сложно, а часто и невозможно, если нет доступа к нужным данным. Поэтому лучше искать их в источниках. Главное место для поиска — Google Dataset Search. Он позволяет по ключевому слову искать датасеты по всему миру. Много датасетов хранится на Kaggle — площадке для соревнований по машинному обучению. Придётся перебирать много нишевых наборов данных, но среди них можно найти полезные для бизнеса.
Примеры датасетов, открытых для использования
● World Bank Open Data. Наборы данных о демографии и экономических показателях.
● IMF Data. Датасеты о финансах и ценах на товары.
● Google Trends. Данные о поисковой статистике и трендовых запросах.
● xView. Большой набор воздушных снимков Земли с аннотациями.
● Labelme. Большой датасет с уже размеченными изображениями.
● Labelled Faces in the Wild. 13 тысяч размеченных изображений лиц.
● HotspotQA Dataset
. Датасет с вопросами-ответами для генерации ответов на часто задаваемые простые вопросы.
● Berkeley DeepDrive BDD100k. Тысячи часов вождения для обучения автопилотов.
● MIMIC-III. Обезличенные медицинские данные пациентов.
● CREMA-D — датасет для распознавания эмоций по записи голоса.
Часто бывает так, что датасета по конкретному запросу не существует. Например, если речь про список клиентов конкретного магазина. В таком случае датасет может предоставить компания, либо его придется формировать самостоятельно: собирать данные и очищать их вручную или автоматически. Часто такие задачи отдают на аутсорс — есть компании, которая занимается подготовкой датасетов из сырых данных.
Совет от эксперта
Мария Ефимова
«Чтобы понять, как датасеты выглядят и что с ними делать, лучше всего взять и поработать с ними на практике. Например, зайти на Kaggle, выбрать интересный датасет и попробовать его проанализировать. Лучшее обучение — это практика».
Ревьюер направления Data Analysis Латинской Америки

Что такое машинное обучение

Как ETL-процессы помогают анализировать большие данные


Учитесь на майских и получайте скидку 7%. Пройдите первый бесплатный урок с 1 по 14 мая и получите промокод на скидку.
Компьютеры понимают только числа. Чтобы обучить машину естественному (человеческому) языку, мы должны перевести все слова в числовой формат. Для этого можно использовать встраивание слов — Word2Veс.

Вместе с Марией Обедковой, NLP Engineer в TrustYou, разбираемся, как работает Word2Vec (на примере Python-библиотеки Gensim).
Как превратить текст в числа
Обработка естественного языка (NLP) начинается с преобразования текста в числа — векторизации. Текст разбивают на части (токены) — символы, слова или предложения, — а затем присваивают числовое значение каждой части (в зависимости от частоты, с которой токен встречается в тексте). Токену можно назначить не одно число, а вектор, состоящий из нескольких чисел.
Word2Vec — одна из реализаций предварительно обученного векторного представления слов от Google.
Создавать векторы можно с помощью подходов One-Hot Encoding и Embedding. В One-Hot Encoding каждый вектор состоит из количества чисел, совпадающего с числом слов в тексте. Все элементы вектора равны 0, кроме того, который соответствует токену.
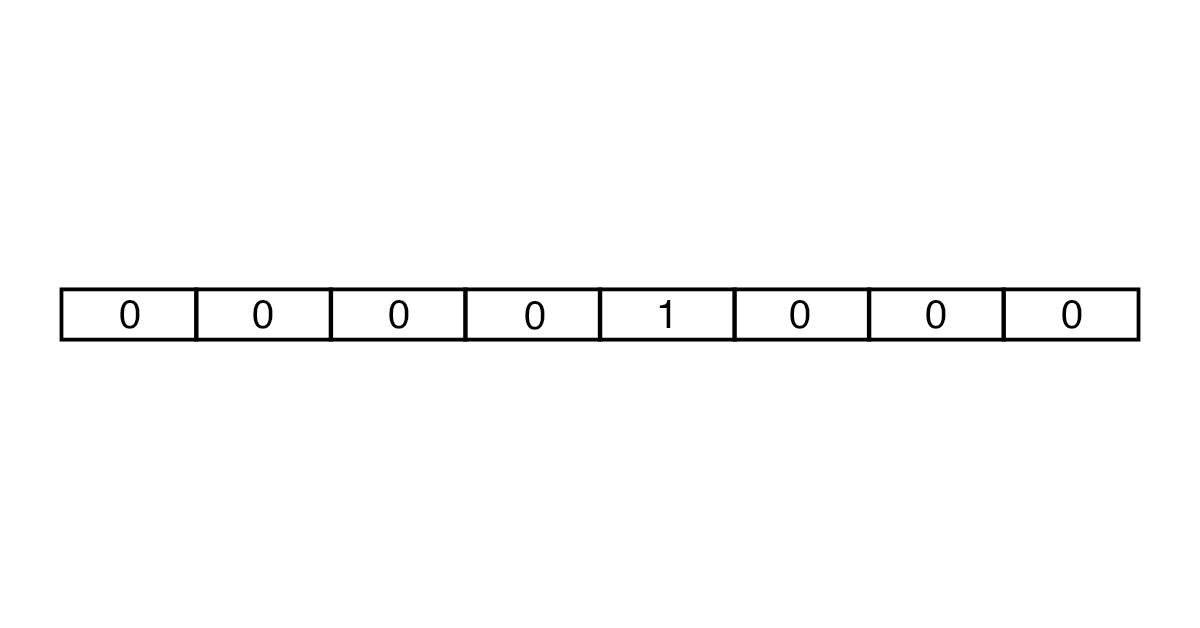
Сначала количество слов для анализа ограничивается с помощью словарей. Для английского языка, например, используют словари Oxford 3000 и Merriam-Webster. Затем создается вектор нужной длины из множества нулей и одной единицы. В итоге получаются векторы большого размера, которые занимают много места в памяти.
Embedding считается более эффективным и менее ресурсоемким. В таком случае вектор может состоять не только из 0 и 1, но и из других чисел. Понадобится меньше «ячеек», чтобы преобразовать слово.
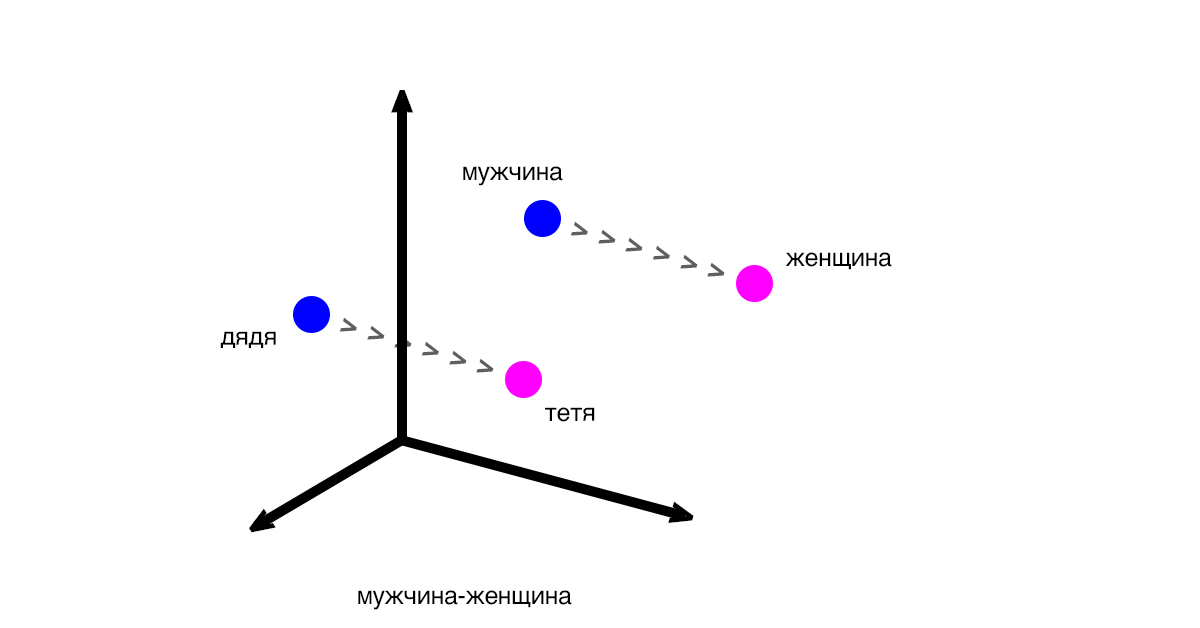
Векторы показывают разницу и закономерности между частями текста (словами, предложениями). Классический пример: вектор между словами «мужчина» и «женщина» будет таким же, как и вектор между словами «дядя» и «тетя».
Расстояния между векторами соответствуют смыслу слов. Выражение «дядя» — «мужчина» + «женщина» будет близким к «тетя», но при этом может не соответствовать ему на 100%.
Мария: «Word2Vec используют как основу для больших проектов и как способ решения исследовательских подзадач. При этом у идеи дистрибутивной семантики (того, что слово можно идентифицировать по контексту) есть недостатки. Например, схожесть слов не всегда указывает на то, что они одинаковы по смыслу».
Поиск синонимов: пишем скрипт
Для работы с Word2Vec можно использовать библиотеку Gensim. Она помогает обрабатывать естественные языки и извлекать семантические темы из документов. Gensim «перегоняет» текст в вектор и считает расстояние между векторами. Преимущество библиотеки в том, что она не требует полной загрузки корпуса в память, а позволяет читать данные с диска.
Рассказываем на примере, как векторные представления помогают находить синонимы для улучшения работы поисковых запросов.
- 1. Загрузим библиотеки для парсинга и анализа страниц.
pip install beautifulsoup4 pip install lxml - 2. Приступим к написанию скрипта и подтянем необходимые зависимости (для парсинга, работы с регулярными изображениями, NLP и Gensim).
import bs4 as bs import urllib.request import re import nltk from nltk.corpus import stopwords from gensim.models import Word2Vec - 3. Будем парсить страницу «Википедии» о романе Филипа Дика Do Androids Dream of Electric Sheep.
scrapped_data = urllib.request.urlopen('https://en.wikipedia.org/wiki/Do_Androids_Dream_of_Electric_Sheep') article = scrapped_data.read() - 4. С помощью объекта BeautifulSoup извлекаем из абзацев текст.
parsed_article = bs.BeautifulSoup(article, 'lxml') paragraphs = parsed_article.find_all('p') - 5. Объединяем весь текст в переменной article_text.
article_text = "" for p in paragraphs: article_text += p.text - 6. Дальнейшая работа любого скрипта зависит от того, насколько хорошо вы провели очистку исходного текста. Поэтому мы переводим все символы в нижний регистр.
cleaned_article = article_text.lower() - 7. Оставляем только буквы и убираем пробелы, используя регулярные выражения.
cleaned_article = re.sub('[^a-z]', ' ', cleaned_article) cleaned_article = re.sub(r's+', ' ', cleaned_article) - 8. Готовим датасет для обучения.
all_sentences = nltk.sent_tokenize(cleaned_article) all_words = [nltk.word_tokenize(sent) for sent in all_sentences] - 9. Проходимся по датасету и удаляем стоп-слова (те, которые не добавляют смысла, например, is).
for i in range(len(all_words)): all_words[i] = [w for w in all_words[i] if w not in stopwords.words('english')] - 10. Создаем модель Word2Vec со словами, чаще всего встречающимися в тексте. Например, теми, которые встречаются минимум 3 раза (min_count=3).
word2vec = Word2Vec(all_words, min_count=3) - 11. В рамках модели находим и выводим самое близкое по смыслу (topn=1) слово для book.
print(word2vec.wv.most_similar('book', topn=1))
Готово — ближайший синоним слова book по нашему словарю — novel.
[(‘novel’, 0.26558035612106323)]
Таким же образом можно искать близкие значения к отдельным словам и целым запросам.