Data science — это сфера, для работы в которой нужны знания предметной области (например, биологии, если вы планируете заниматься биоинформатикой), навыки программирования, а также подготовка по математике и статистике. Специалисты по данным помогают компании обрабатывать огромный пул информации из разных источников. В data science есть много профессий со схожими названиями: например, разработчики ML и ML-инженеры. Академия Яндекса совместно с преподавателями ШАДа разобралась, что важно знать всем ML-специалистам, чем отличаются профессии в этой области и чего ждут от кандидатов на разные вакансии.
Как устроена сфера data science
В data science есть пять основных направлений:
1. Машинное обучение — это фундамент наук о данных. Оно позволяет обучать нейросети, чтобы автоматизировать сложные задачи. Например, можно научить модель отличать изображения молока от сметаны, чтобы потом вести статистику по покупкам в магазине.
2. Моделирование помогает делать быстрые вычисления на основе имеющихся данных. Можно изучить 100 покупок человека и в 101 раз помочь ему собрать корзину: кажется, вы очень любите клубничные пончики, не хотите добавить их в заказ?
3. Статистика позволяет извлекать больше информации из данных и получать более точные, статистически значимые результаты. К примеру, мы не можем делать выводы о миллионах клиентов, посмотрев на данные для ста, выбранных случайно.
4. Программирование нужно для того, разработчики могли создавать модели и реализовывать другие свои решения. Чаще всего датасаентисты используют Python или R.
5. Базы данных позволяют эффективно хранить информацию: ведь у крупных компаний копится огромное количество данных.
Науки о данных позволяют компаниям решать такие задачи:
— Классифицировать контент (например, отличать спам от полезных писем)
— Находить аномалии (такие, как мошенничество или попытки взлома)
— Распознавать текст, изображения, аудио, видео, лица и так далее
— Автоматизировать принятие решений (к примеру, выдавать человеку кредитную карту или нет)
— Сегментировать группы клиентов
Какие инструменты используют датасаентисты
В зависимости от того, в какой компании и с какими данными работает датасаентист, будут отличаться языки программирования, методы и библиотеки. Поэтому мы перечислим только самые популярные из них:
— Языки программирования: Python, R, SQL, Java или Scala
— Библиотеки: Scikit-learn, TensorFlow, PyTorch, Pandas, Numpy и Matplotlib
— Cреды разработки: Jupyter и JupyterLab
— Фреймворки: Hadoop, Spark, Kafka, Hive, Pig, Drill, Presto и Mahout
— Cистемы управления базами данных: MySQL, PostgreSQL, Redshift, Snowflake, MongoDB, Redis, Hadoop и HBase
Датасаентисту не обязательно владеть всеми этими инструментами: есть специализации, которые позволяют фокусироваться на том, что нравится больше. К примеру, исследователи больше работают с построением моделей и намного меньше — с базами данных. Разберёмся, что же важно уметь и знать исследователям, аналитикам, ML-разработчикам и инженерам.
Исследователь
Основная задача исследователя — улучшать качество моделей машинного обучения. В целом его работу можно разделить на два блока. Первый — работа с готовой моделью в проекте. Необходимо непрерывно оценивать ее качество и находить, что в ней можно улучшить. В этом помогают онлайн- и офлайн-метрики, а также обратная связь от тестировщиков.
Второй — непосредственно исследовательская часть: поиск новых архитектур и сигналов для предсказания. Например, в группе беспилотников Яндекса еженедельно проходят научные семинары, где специалисты читают и обсуждают научные статьи по своей и смежным областям.
Основную часть времени занимает обучение новых моделей. Например, подготовка данных на кластере и написание инфраструктуры для эффективного обучения. Также в обязанности входит деплой модели: нужно написать модель и проверить, что на реальных данных она ведет себя ожидаемым образом, а затем уже оптимизировать ее производительность.
Что нужно знать исследователю:
— Python, чтобы разрабатывать модели
— C++, чтобы внедрять код в продакшн
— Фреймворки для глубинного обучения (TensorFlow, PyTorch, Caffe или другие)
— Структуры данных и алгоритмы
Ещё важно активно следить за выходящими публикациями (например, c помощью Google Scholar или ArXiv), быстро читать много научной литературы в области своих исследований. Помимо этого важен навык написания статей и общения с рецензентами: даже качественное исследование само может оказаться непонятным для ваших коллег-учёных, поэтому его необходимо грамотно описать и представить.
ML-разработчик
Обязанности разработчика очень похожи на исследовательские. Но в отличие от него не нужно готовить публикации в научных журналах и регулярно разрабатывать принципиально новые технологии. Гораздо важнее, чем для исследователя, умение писать эффективный и читаемый код, в котором потом смогут разобраться коллеги.
Также полезно владеть инструментами для совместной разработки и уметь не только обучать качественные модели, но и создавать на их основе сервисы, способные выдерживать высокую нагрузку: это может требовать владения как более низкоуровневыми языками программирования, так и техниками для оптимизации моделей машинного обучения.
Что нужно знать разработчику:
— Python и С++, чтобы разрабатывать модели и обучать алгоритмы
— Теорию вероятности, математическую статистику и дискретную математику
— Фреймворки Deep Learning (TensorFlow, PyTorch, Caffe или другие)
У ML-разработчиков могут быть разные профессиональные интересы: например, компьютерное зрение или обработка естественного языка. Исходя из них можно выбрать подходящее направление работы и сервис. Например, в геосервисах Яндекса разработчики занимаются улучшением качества поиска маршрута или предсказанием времени пути и активно работают с изображениями и видео. А датасаентисты в Переводчике занимаются текстовыми моделями и, предсказуемо, работают в основном с текстом.
Дата-инженер
Инженеры занимаются подготовкой данных для последующего анализа. Их задача — сначала собрать данные из соцсетей, сайтов, блогов и других внешних и внутренних источников, а затем привести в их структурированный вид, который можно отправить аналитику.
Объясним на пальцах: представьте, что вам нужно приготовить яблочный пирог. Сначала нужно найти муку, яблоко, яйца, молоко и другие ингредиенты из рецепта. Этим и занимается инженер, только он ищет и приносит нужные данные. А вот аналитик уже будет готовить сам пирог, а точнее искать закономерности среди найденных данных.
Что нужно знать дата-инженеру:
— Как проектировать хранилища, настраивать сбор данных и дата-пайплайнов
— Как построить ETL-процессы
— C++, Python или Java
— SQL для работы с базами данных
Кроме того, инженеры создают и поддерживают инфраструктуру по хранению данных. Они же отвечают за ETL-систему, то есть извлечение, преобразование и загрузку данных в одно хранилище. Можно сказать, что они отвечают за покупку и хранение ингредиентов для пирога: чтобы аналитик мог взять их в любое время, когда понадобится приготовить блюдо, и быть уверенным, что всё на месте и ничего не испортилось.
Аналитик данных
Аналитики данных помогают компании улучшать метрики и решать промежуточные задачи (к примеру, увеличивать конверсию в платящих пользователей), а не двигаться к большим целям (двукратному увеличению прибыли через год) вслепую. Чаще всего они работают в плотной связке с продактами.
Задача аналитика — обработать большой объем данных и найти в нем закономерности. Например, он может узнать, что чаще всего зубные щетки «Чистозуб» покупают женатые мужчины от 30 до 40 лет. Или кому не нужно выдавать кредиты. Аналитики помогают компаниям лучше понимать своих клиентов и, следовательно, зарабатывать
В работе они используют знания математической статистики, которые позволяют им находить закономерности, предсказывать поведение пользователей. Ещё аналитики данных проводят тесты, проверяют, как пользователи реагируют на новый интерфейс, и помогают оптимизировать бизнес-процессы.
Что нужно знать аналитику:
— Python, чтобы обрабатывать данные
— Математическую статистику, чтобы выбирать нужные методы для обработки данных
— Диалекты SQL: например, ClickHouse или YQL
— DataLens, Tableau и другие инструменты для построения дашбордов
— Инструменты для работы с большими данными: например, Hadoop, Hive или Spark
Резюме
В data science есть множество направлений и задач для тех, кто любит точные науки. Можно заниматься наукоемкими задачами в роли исследователя, внедрять новые технологии в качестве разработчика, искать полезные закономерности для бизнеса на должности аналитика или собирать и структурировать данные, если вы выбрали работу инженера. Кроме того, при выборе вы можете опираться не только на свои знания, но и на то, какие проблемы вы хотите решать: возможно, вы мечтаете искать мошенников и помогать законопослушным пользователям — или двигать вперёд науку и создавать технологии, которыми будут пользоваться другие.
Анализ данных • 24 августа 2022 • 5 мин чтения
Почему эти профессии похожи, как их не перепутать и какую выбрать.
- Data Science и аналитика данных: в чём сходства и различия
- В чём разница между профессиями Data Scientist и аналитик данных
- Куда развиваться в профессии аналитику данных и специалисту по Data Science
- Совет эксперта
Data Science и аналитика данных: в чём сходства и различия
Суть аналитики в том, чтобы визуализировать данные и делать выводы на их основе. Data Science включает в себя оба эти этапа плюс машинное обучение (англ. Machine Learning) и глубокое обучение (англ. Deep Learning), с помощью которого специалисты строят и запускают модели для прогнозов.
Обе области пытаются предсказать, как данные повлияют на показатели компании, и предложить лучшие гипотезы, как корректировать поведение пользователей, чтобы достичь результатов. Например, какому сегменту клиентов точно стоит отправлять рассылку, какой отклик планируется получить и окупится ли вложенный в это бюджет. Аналитика данных и Data Science являются разными этапами одного процесса.

Аналитика данных — это отрасль Data Science, которая фокусируется на интерпретации полученных выводов, в то время как для Data Science важнее корреляции между большими массивами данных
Анализ больших данных: зачем он нужен и кто им занимается

В чём разница между профессиями Data Scientist и аналитик данных
Чем занимается Data Scientist
Специалисты по Data Science большую часть времени проводят за очисткой данных: подготавливают их для моделей и алгоритмов, обнаруживающих скрытые закономерности, которые не может выявить человек. Данные клиента загружают в модель и заставляют её строить прогнозы, на основании которых потом принимаются ключевые решения в бизнесе. Например, какой бюджет выделить на производство новой линейки товаров, какой процент выручки получит компания от их реализации и за какие сроки.
Чем занимается аналитик данных
Главное отличие аналитика данных от специалиста по Data Science в том, что аналитик не владеет навыками машинного обучения, поэтому сам обрабатывает данные. Например, собирает у маркетологов все данные по прошлым рассылкам компании и сегментирует пользователей по возрасту, полу, локации, предпочтениям. Затем выявляет в данных закономерности и влияние параметров друг на друга.
Аналитик занимается ретроанализом, то есть анализом прошлого поведения пользователей, и на его основе ищет связи между эффективностью рассылки и показателями компании, предлагает рекомендации. Для специалиста по Data Science и для аналитика критически важны продвинутые знания доменной области — индустрии, в которой они работают, будь то ретейл, промышленность или финансы.
Аналитика данных и Data Science могут улучшить процесс принятия решений только при условии понимания того, как выбор влияет на результаты. Поэтому специалисты по данным должны сочетать инструменты машинного обучения с пониманием причинно-следственных связей, стоящих за данными. На курсе «Аналитик данных» эти навыки можно освоить с нуля за 6 месяцев.
Решайте задачи с помощью машинного обучения
Попробуйте себя в роли специалиста по Data Science: находите неочевидные закономерности в данных, стройте гипотезы, обучайте алгоритмы.
Начните курс с бесплатной вводной части.

Сходства и различия задач дата сайентиста и аналитика данных
У них разные методы и подходы решения одной задачи — правильно повлиять на менеджерское решение, чтобы увеличить продажи. Например, спрогнозировать сезонный спрос на товары, которые производит клиент. Для этого можно было бы поставить аналитику задачу провести ретроанализ продаж и сделать сезонную кривую. Либо попросить специалиста по Data Science проанализировать частотность запросов в семантическом ядре и произвести другую сезонную кривую.
Эти данные будут отличаться, потому что алгоритм чаще всего находит закономерности лучше, чем человек вручную, и быстрее собирает данные. Результаты работы аналитика и специалиста по Data Science в деталях будут разными: корреляцию, которую нашёл Data Scientist, может не найти аналитик, потому что у него не хватает для этого инструментов.
В зависимости от того, какие данные используются, можно принимать разные решения в бизнесе. Например, юзабилити сайта можно улучшать на основании данных о поведении пользователей, и увеличить средний чек, провоцируя их покупать больше или чаще.
У аналитика данных и специалиста по Data Science разный фокус. Аналитик должен не просто визуализировать данные и строить серьёзные графики, а обладать навыком доносить информацию до коллег, которые не погружены в неё настолько глубоко.
Поэтому аналитику гибкие навыки нужны больше, чем специалисту по Data Science. Например, руководитель ставит задачу проанализировать результаты маркетинговой кампании. Аналитик данных пойдёт к маркетологам, соберёт и обработает их данные, затем сведёт в отчёт и проведёт презентацию перед руководством для принятия решения.
На этапе сбора данных Data Scientist тоже обратится к маркетологам, но потом 60% времени будет занят программированием и работать с данными, а не с людьми.
Эти примеры характерны для маленьких компаний или стартапов. В больших компаниях специалисты по данным работают в кросс-функциональных командах, где есть ML-инженер, Data Scientist и аналитики данных. За глубокими знаниями доменной области Data Scientist сможет обратиться к коллеге-аналитику, а ML-инженер будет следить, чтобы созданный специалистом по Data Science алгоритм работал без ошибок.
Сравнение навыков

Сходства и различия образования и опыта работы
Аналитику данных и специалисту по Data Science нужно математическое или техническое образование. Для обоих важны знания доменной области. Различие в том, что у аналитика, который обрабатывает и интерпретирует данные сам, эти знания должны быть глубже. А Data Scientist должен знать языки программирования, чтобы обучать алгоритмы.
Для получения опыта у специалистов по Data Science есть хакатоны и курсы. Для аналитиков — образование и работа в проектах, потому что соревнований, где можно набить руку в решении задач по аналитике данных, немного.
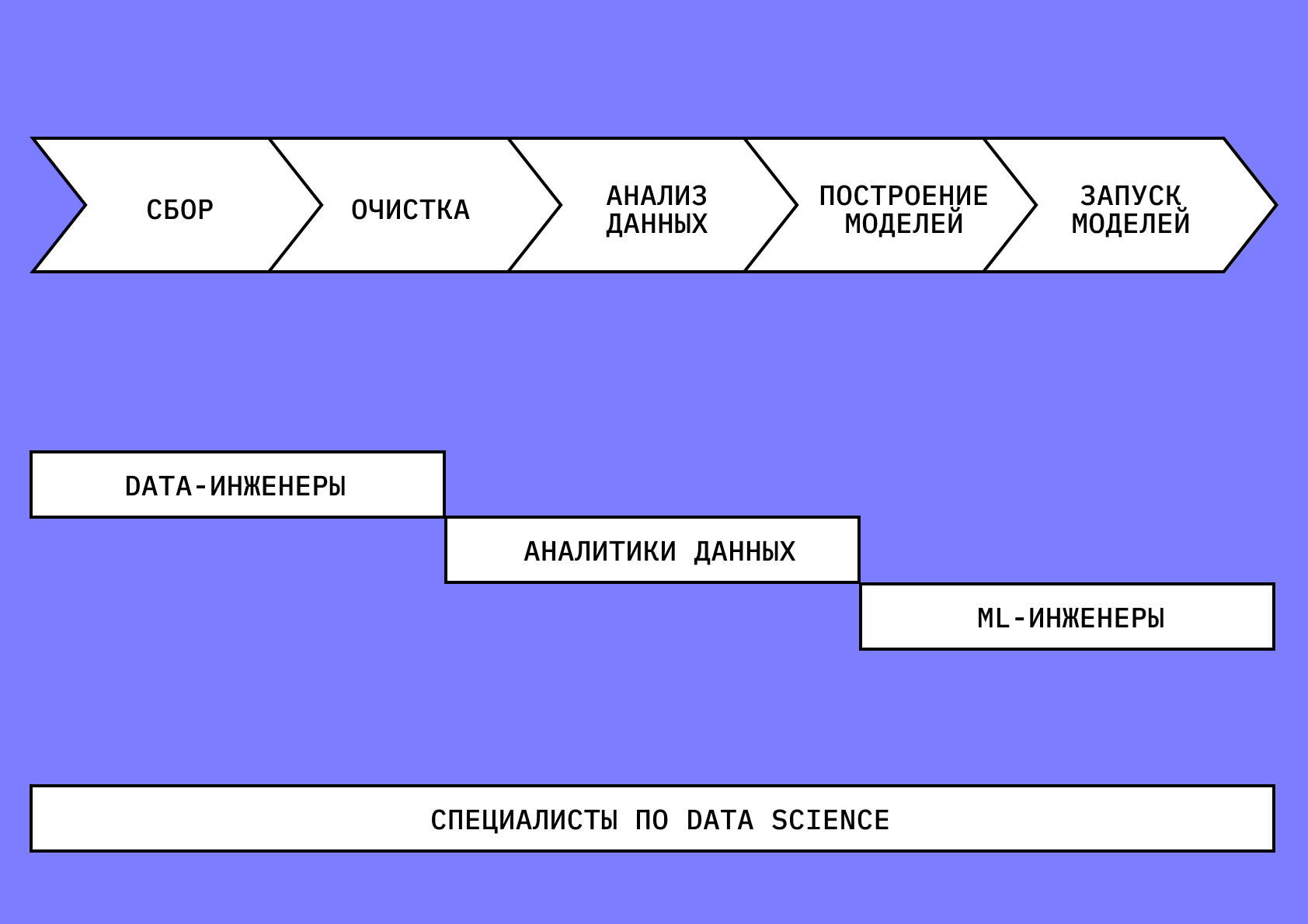
В процессе работы с данными Data Scientist подхватывает результаты работы аналитика и загружает их в модель для построения прогнозов, которую будет обучать с помощью ML-инженера
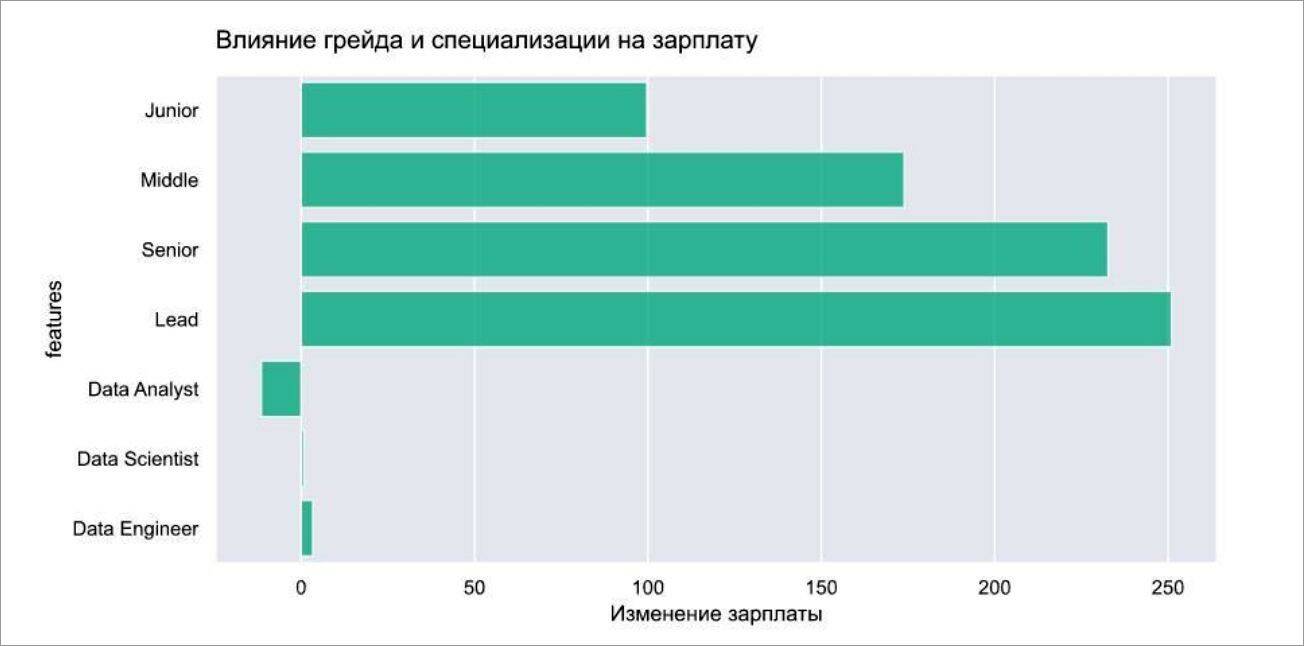
Данные исследования за 2018–2021 гг.
По данным Open Data Science, аналитикам платят примерно на 11–14 тыс. меньше, чем специалистам по Data Science. На то, сколько зарабатывают специалисты, сильнее влияет опыт и уровень: при переходе от джуна к мидлу зарплата в среднем растёт на 74 тыс. (71%), от мидла к синьору — на 58 тыс. (32%). От синьора к лиду — всего на 17 тыс. (7%).
Куда развиваться в профессии аналитику данных и специалисту по Data Science
Аналитик данных может стать специалистом по Data Science — для этого нужно будет изучить машинное обучение, языки программирования и набраться опыта в проектах или же выбрать развиваться в менеджменте и расти в управленческой роли. Data Scientist может стать сеньором или тимлидом.
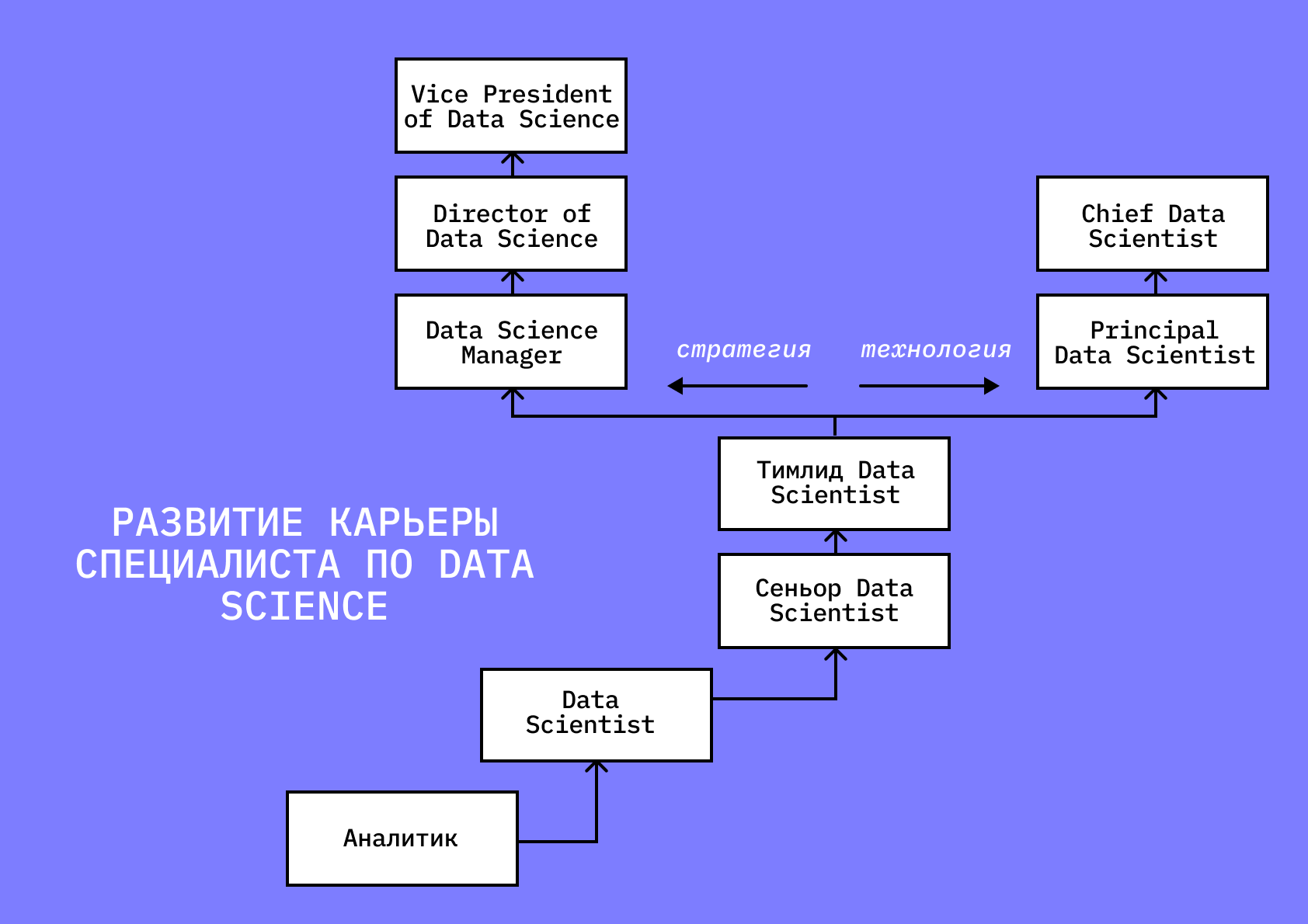
В каждой компании схемы роста могут выглядеть по-разному: например, аналитики данных и специалисты по Data Science могут работать в разных отделах и иметь свои грейды, а где-то аналитик считается начальной ступенью на пути в Data Science
Как стать аналитиком данных
Бесплатный гайд для начинающих: какие задачи решает и сколько времени тратит на обучение аналитик данных.

Совет эксперта
Егор Кузнецов
«Если вы хотите стать специалистом по Data Science, но не обладаете достаточными знаниями машинного обучения или программирования, то я советую начать с позиции аналитика данных. Подобные вакансии есть практически в каждой компании под разные требования. Начните набивать руку на реальных задачах, постепенно обучаясь недостающим навыкам. И тогда ваш выбор профессии станет более осознанным, а погружение более плавным».
Леонид Кузьмин
Винлаб
SEO специалист, 10 лет занимается аналитикой данных
Егор Кузнецов
Яндекс Практикум
Наставник курса «Специалист по Data Science», Senior Data Scientist розничной сети «Магнит»
Юлия Слуцкая
Яндекс Практикум
Редактор


Чем занимается аналитик данных, почему он всем так нужен и как освоить эту профессию
Кто я аналитик данных или датасаентист?
Уровень сложности
Простой
Время на прочтение
3 мин
Количество просмотров 1.1K

По данным аналитической компании IDC, в 2020 году в мире было произведено более 64 зеттабайт данных (для справки: 1 зеттабайт равен 10²¹ байтов). По прогнозам, к 2025 году объем всех данных в мире составит 175 зеттабайт. Важно подчеркнуть, что эта тенденция растет, и правильное использование данных может сыграть решающую роль в развитии многих отраслей. Глобальный рост объема информации еще раз подчеркивает незаменимость и актуальность профессий по работе с анализом данных.
Привет, Хабр! Меня зовут Алексей. И вот уже около 2 лет я работаю в компании Мегапьютер аналитиком данных. А есть еще одна профессия, связанная с обработкой данных – это Data Scientist.
В 50% статей в интернете написано, что аналитик данных и Data Scientist (датасаентист) это одно и тоже, а другие 50% — за абсолютную разницу данных профессий. Одной из ключевых задач аналитика является обработка данных, такая же задач стоит и перед Data Scientist. Я решил понять к какой профессии я больше отношусь и почему.
Разбираемся. Big Data Analyst переводится как аналитик больших данных, кем я работаю, а Data Scientist переводиться как специалист по изучению или обработки данных. Яндекс Практикум дает такую формулировку и разбивает способности на такие критерии. Отличия аналитика данных от data scientist: в чем разница между специальностями (yandex.ru)

Буду рассказывать о себе опираясь на данную таблицу.
Образование у меня техническое, специальность — защита информации. Прошел обучение по работе в системе по аналитике данных PolyAnalyst. Программирование я не изучал, что мне и не требуется. Математическими знаниями обладаю.
На работе занимаюсь анализом больших объемов информации, предоставляемых компанией. Аналитические выводы визуализирую и выстраиваю графики в BI системе компании. Python не знаю и данные в нем не обрабатываю.
Датасайентист выполняет обработку разнообразных данных. Данные, с которыми он работает, условно можно разделить на несколько ключевых групп.
1. Структурированные данные представляют собой фактическую и точную информацию. Чаще всего они представлены в форме букв и цифр, которые хорошо вписываются в строки и столбцы таблиц. Структурированные данные обычно существуют в таблицах, подобных файлам Excel или Google Sheets. К структурированной информации относят данные, полученные из кассового аппарата либо из других устройств.
2. Полуструктурированные данные — это подвид структурированных данных. К ним относятся сообщения, которые приходят на электронную почту, статистические данные из определенных трекеров событий.
3. Неструктурированные данные не имеют заранее определенной структуры и представлены во всем разнообразии форм. Это видео, звук, изображения. В том числе это и текстовые файлы, например DOC или PDF. Один из видов неструктурированной информации — это посты в социальных сетях.
Из-за того, что большая часть информационных данных не структурирована, есть некоторые сложности с анализом. И для достижения требуемого результата Data Scientist применяет машинное обучение (Machine Learning) и глубокое обучение (Deep Learning) либо же иные технологии. Это позволяет отыскивать требуемые данные, а также определять скрытые закономерности. Я в своей работе тоже использую все типы данных, только прогнозы не строю, агрегирую, свожу и обрабатываю данные в настоящем моменте. Результаты своего анализа вывожу на дашбордах аналитической платформы PolyAnalyst.
Остался последний пункт для сравнения – Soft skills (гибкие навыки). Что это такое? Выясняем.
Ги́бкие или надпрофессиональные на́выки (также англ., soft skills) — комплекс умений общего характера, тесно связанных с личностными качествами. Они включают умения организовывать командную работу, вести переговоры и договариваться с коллегами, креативность, способность учиться и адаптироваться к изменениям.
Аналитическая работа часто предполагает работу в команде, особенно над крупным проектом, взаимодействие с другими сотрудниками, сбор информации для анализа. Адаптация и умение договариваться просто необходимы для коммуникации с клиентом, возможности понять цели и задачи проекта, требования и пожелания к работе над ним. Гибкими навыками тоже обладаю.
Подводим итоги: я получился 100% аналитик данных по всем заявленным данной таблицей критериям, так как у меня есть все профессиональные компетенции, необходимые для успешной работы в своей области.
Наш прогрессивный мир не стоит на месте. И чтобы быть востребованным на волне развития, чтобы привнести в свою работу прогрессивные методы анализа, нужно постоянно учиться новому и получать инновационные знания.
Сейчас читаю книгу «Измеряйте самое важное» Джон Дорр и прохожу курс «Основы работы с DataLens».
Профессии, связанные с обработкой и анализом данных, часто путают. Требования к Data Scientist, Data Analyst и Data Engineer могут отличаться в зависимости от целей, которые конкретная компания хочет достичь с помощью данных. При этом различия между этими специализациями достаточно четкие, а их понимание поможет оценить свои компетенции и не тратить время, откликаясь на нерелевантные вакансии.
Как бизнес работает с данными
Прежде, чем перейти к специализациям, разберемся, как компании получают данные и где их хранят.
С того момента, как пользователь заходит на сайт, все его действия отслеживаются и фиксируются. Сайт следит за тем, какую музыку он слушал, в какой стране находится, сколько времени провел, читая тексты или смотря видео. Вся эта информация записывается и отправляется на сервер — он может быть локальным или облачным, в зависимости от объема данных и специфики компании.
На сервер чаще всего попадают «сырые», неструктурированные данные, которые не удастся получить, просто обратившись к ним. Сначала их нужно перенести в базу данных, предварительно преобразовав в нужный формат и очистив от лишней информации. Например, перевести данные, записанные в строку, в табличный формат, выровнять их в соответствии с требованиями JSON и проверяются на достоверность.
Процесс очистки и преобразования данных в удобный формат называется ELT — это аббревиатура, которая расшифровывается как извлечение (extract), преобразование (transform) и загрузка в базу данных (load).
До этого этапа разделения на Data Scientist, Data Analyst и Data Engineer не существует — очисткой и преобразованием данных занимаются все перечисленные специализации. Различия зависят от того, какие именно действия нужно выполнять с данными. Разбираем разницу между ними вместе с карьерными коучами Elbrus Bootcamp.
Data Analyst
На основе данных, собранных в прошлом, аналитик оценивает текущую ситуацию и отвечает на вопросы «Почему сейчас происходит именно это?», «Каковы причины?», «Хорошо ли работает продукт?», «Что мы можем сделать, чтобы избежать/достичь чего-то?».
Data Analyst может делать трендовые предсказания, но его основная задача — следить за тем, как изменилась ситуация за определенный период времени. Для этого ему нужно глубоко разбираться в метриках и их взаимодействиях друг с другом, знать язык программирования SQL для работы с базами данных и уметь визуализировать результаты своих исследований.
Рассмотрим его работу на примере музыкального стримингового сервиса. В обязанности аналитика в числе прочего входит отслеживание изменений показателей, связанных с поведением пользователей, удобством интерфейса и оценка успешности проведения рекламных кампаний.
Data Scientist
Эта профессия сосредоточена не на анализе настоящего, а на предсказании будущего. Data Scientist строит модели машинного обучения, с помощью которых старается найти зависимости и на их основе создать новые продукты.
В примере со стриминговым сервисом Data Scientist решает бизнес-задачу, как рекомендовать композиции, которые понравятся пользователю. В частности, повышает точность существующих рекомендательных алгоритмов, чтобы увеличить возвращаемость клиента и время прослушивания музыки.
Если для Data Analyst понимание алгоритмов машинного обучения желательно, то для Data Scientist это обязательное требование. Такому специалисту нужно знать большое количество инструментов и методов построения моделей, а также математику и статистику. Кроме того, ему необходимы глубокие знания в программировании, поскольку основной продукт его деятельности — это код.
Стоит отметить, что Data Scientist — это широкий спектр профессий, в числе которых распознавание лиц, оптимизация поисковых алгоритмов, обработка естественного языка и другие. Каждая из них имеет свои особенности — некоторые близки к тому, чем занимается Data Analyst.
Data Engineer
Если две предыдущие специализации делают акцент на использовании данных, то Data Engineer заботится об их подготовке. Он отвечает на вопросы «Какие данные получают Data Analyst и Data Scientist?», «Как данные о поведении пользователя поступают в базу данных?», «Как убедиться, что они отражают реальность?».
Data Engineer строит инфраструктуру хранения и следит, чтобы данные, собранные компанией, были доступны Data Analyst и Data Engineer. В его зону ответственности входит проверка данных на соответствие требованиям — своевременности, чистоте, структурированности и другим.
Такому специалисту кроме знания языка SQL нужно разбираться в облачных вычислениях и программировании.
Заключение
Разделение на специализации скорее теоретическое, чем практическое — оно помогает понять, в какую сторону стоит двигаться начинающему специалисту и на какие вакансии обращать внимание.
В реальном мире один человек в зависимости от требований, навыков и размера компании может совмещать в себе одну и более ролей. Например, Data Scientist может выполнять задачи, которыми обычно занимается Data Analyst, а также поднимать новые сервера и разворачивать кластеры — то есть выполнять действия, которые входят в зону ответственности Data Engineer.
При устройстве на работу может произойти так, что начинающему специалисту придется заниматься аналитикой, моделями и выполнять небольшую часть работы Data Engineer. А его коллега возьмет на себя, например, дата-сайентистские и инженерные задач.
Поэтому некоторые школы программирования при обучении не делают упор на одну из специализаций, а стараются дать знания, которые позволят совмещать разные профессии, связанные с обработкой и анализом данных. Например, студенты Elbrus Bootcamp после выпуска могут работать и как Data Analyst, и как Data Scientist. Для того, чтобы откликаться на вакансии, связанные с Data Engineer, нужно будет получить дополнительные знания и углубить существующие.
В статье рассказывается:
- Что такое Data Science
- Принцип работы Data Science
- Сферы применения Data Science
- Кто такой специалист по Data Science
- Задачи специалиста по Data Science
- Основные инструменты Data Science
- Знания и умения, необходимые для старта в Data Science
-

Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Data science – это сравнительно новая дисциплина в области поиска, хранения и обработки информации. И пусть вас не смущает слово «science», этот инструмент используется повсеместно и к науке имеет определяющее значение, а не связанное. То есть это и есть своего рода наука – работа с данными.
Бизнес активно использует DS для прогнозирования событий, сбора и сегментации целевой аудитории, изучения спроса на те или иные продукты. Подробнее о том, что собой представляет data science, чем занимаются специалисты из этой области и что нужно, чтобы начать работать в этой сфере, вы узнаете из нашего материала.
Data Science — это дисциплина, повышающая полезность данных. Можно найти разные определения этого понятия и в каждом из них будет присутствовать слово «данные». То есть Data Science применяется очень широко.
Это приводит к тому, что деятельность специалиста в этой области сложно дифференцировать: не вполне понятно, чем именно он занимается, работая с данными, ведь они нужны и для создания отчетов, и для прогнозирования спроса в той или иной области, и для построения сложных математических моделей динамического ценообразования, и для настройки поточной обработки данных для высоконагруженных сервисов, работающих в режиме реального времени.

Слово «наука» в названии используется не просто так. Математика для Data Science является базой, анализ данных основан на классическом математическом аппарате: теории оптимизации, линейной алгебре, математической статистике и не только. Однако наука является фундаментом, а не основной областью деятельности специалистов, большинство из которых занимаются не теорией, а практикой, решают конкретные проблемы.
Разумеется, существуют крупные корпорации с большим штатом сотрудников, занимающихся исключительно научной работой, они создают новые алгоритмы и методы машинного обучения, а также улучшают уже имеющиеся.
Сегодня бизнесу хочется в первую очередь понимать, какой положительный эффект может оказать на него Data Science. Важно не то, как строятся модели с помощью алгоритмов машинного обучения, а почему вообще возникла потребность в их создании, как она была сформулирована в математическом ключе и реализована в конкретных способах решения задач.
Огромное значение имеет и проведение честных экспериментов, которые помогают правильной оценке эффективности примененных моделей работы в конкретном бизнесе.
Принцип работы Data Science
Рассмотрим теоретические основы науки о данных. Data science в русскоязычной среде просто транслитерируется – «дата сайенс». Это понятие понимается как совокупность ряда взаимосвязанных дисциплин и методов из области информатики и математики.
Скачать файл
Первая часть: data
В науке о данных сами данные очевидно занимают определяющее значение. Особое значение имеют методы их сбора, хранения, обработки, а также вычленения из общего массива данных полезной информации. Процесс получения этой выжимки занимает до 80 % рабочего времени специалистов этой области.
Существуют данные, которые не могут быть собраны и обработаны традиционными способами в виду их большого объема и/или разнообразия – их называют большими данными, или big data.
Важно! big data science является подразделом data science, а не ее синонимом. Однако в реальности дата-аналитики зачастую работают именно с большими данными.
Рассмотрим это на примере.
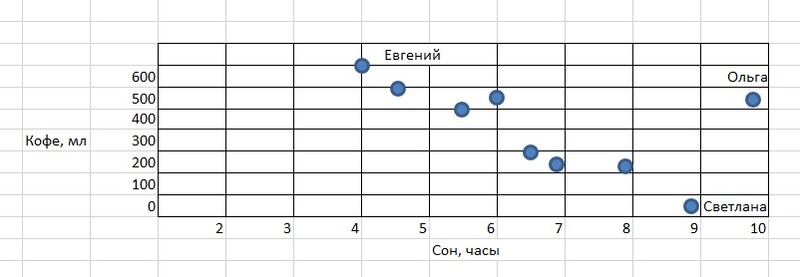
Попробуем проследить взаимосвязь между количеством чашек кофе, которые пьют сотрудники компании в течение дня, и тем, сколько они спали этой ночью. Имеется доступная информация: менеджер Евгений спал накануне 4 часа, после чего выпил 3 чашки кофе, Светлана спала 9 часов и не выпила ни одной чашки кофе, а Ольга спала 10 часов, но выпила 2,5 чашки кофе. Данные можно собирать по всем сотрудникам при необходимости.
Построим график на основе полученной информации о сне менеджеров и выпитых ими чашках кофе (кстати визуализация является важной составляющей любого data science-проекта). Ось X – это время в часах, ось Y – кофе в миллилитрах. Получим такой результат:
Вторая часть: science
Полученные данные нужно каким-то образом обработать, построенный график по идее должен привести нас к конкретным выводам. Для этого информацию следует проанализировать, извлечь из нее полезные закономерности и затем использовать. И вот тут активируется вторая часть data science, а именно такие дисциплины, как статистика, машинное обучение, оптимизация.
Благодаря им и формируется анализ данных. Машинное обучение обеспечивает поиск закономерностей в имеющихся данных, для того чтобы в дальнейшем иметь возможность предсказывать нужную информацию для новых объектов.
В нашем примере мы видим некоторую взаимосвязь между количеством сна и потребностью в кофе: чем меньше сна, тем больше хочется взбодриться тонизирующим напитком. Однако Ольга, которая и спит хорошо, и кофе очень любит, является исключением из общей картины. При этом мы все равно должны попытаться отразить закономерность общей прямой линией таким образом, чтобы она максимально близко подходила ко всем точкам.
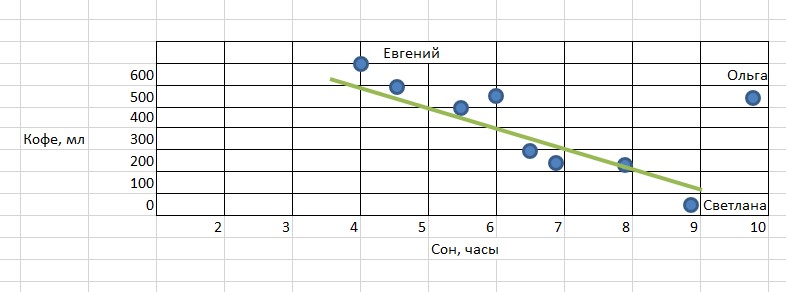
Зеленая линия представляет собой модель машинного обучения, она обобщает данные и имеет математическое описание. Пользуясь этой моделью, можно определять значения для новых объектов. То есть зная, что новый сотрудник Сергей спал сегодня 7,5 часов, мы сможем предсказать, что в течение дня он выпьет около 300 мл кофе. Для этого просто подставим значение в модель. Красная точка – это наше предсказание.
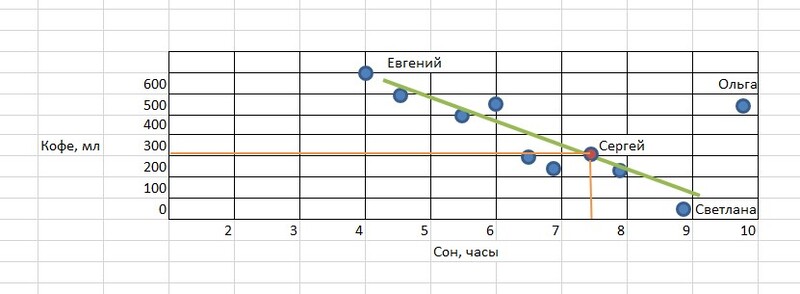
Основная идея машинного обучения довольно проста: обнаружить закономерность и применить ее к новым данным. Но существует еще одна группа ключевых задач, которая имеет целью не предсказание каких-то значений, а разбивку данных на некоторые группы.
Data science-проект является прикладным исследованием, в котором обязательны такие этапы, как постановка гипотезы, разработка плана эксперимента и оценка результата его пригодности для решения определенной задачи. Это имеет огромное значение в сфере бизнеса, когда необходимо понять, будет ли польза от принятия конкретного решения.
Если вернуться к нашему примеру с кофе, то по результатам исследования можно было бы определить количество напитка, которое требуется сотрудникам офиса в течение месяца, и сделать закупку в соответствие с реальными потребностями людей. Однако проведя расчеты, необходимо сравнить полученную модель с уже существующей и выявить лучшую.

Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда

Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
Уже скачали 20630 ![]()
Даже в этом примере можно было бы построить более сложный и точный график, учитывающий, например, любовь к кофе каждого отдельного сотрудника, а также другие параметры. А модель могла бы находить более сложные взаимосвязи и представлять собой не прямую линию, а что-то иное. Допустим, Ольга – явное исключение из правила, и она могла стать так называемым выбросом, то есть объектом, отличающимся от остальных.
Такие объекты негативно влияют на процесс построения модели и ее качество, их нужно обрабатывать иначе. А бывает и так, что именно они имеют первостепенную важность для исследования. Это происходит, например, при обнаружении нестандартных банковских операций с целью предотвращения мошенничества.
Стоит также отметить, что необычное поведение Ольги указывает нам на несовершенство алгоритмов машинного обучения. То есть в модели, которая была создана по результатам исследования, дается прогноз в виде потребности человека в 100 мл кофе после 10 часового сна, при этом Ольга выпила 500. Однако создать идеальную модель, которая устранит все возможные противоречия и даст абсолютно точный прогноз, невозможно.
Как бы хорошо не были собраны и проанализированы данные, всегда есть исключения, нарушающие идеальную целостность полученной картины.
Сферы применения Data Science
По данным компании Kaggle, которая представляет собой профессиональную социальную сеть для специалистов описываемой нами области, сегодня data science аналитика используется бизнесом любого масштаба. IDC и Hitachi отмечают, что 78% предприятий подтверждают серьезный рост количества анализируемой и используемой информации за последнее время.

Предприниматели отдают себе отчет в важности информации и необходимости ее структурирования с целью положительного влияния на собственную деятельность независимо от ее направленности. Перечислим отрасли, в которых Data Science активно используется для решения текущих задач:
- онлайн-торговля и развлекательные сервисы: рекомендательные системы для пользователей;
- здравоохранение: прогнозирование заболеваний и рекомендации по сохранению здоровья;
- логистика: планирование и оптимизация маршрутов доставки;
- digital-реклама: автоматизированное размещение контента и таргетирование;
- финансы: скоринг, обнаружение и предотвращение мошенничества;
- промышленность: предиктивная аналитика для планирования ремонтов и производства;
- недвижимость: поиск и предложение наиболее подходящих покупателю объектов;
- госуправление: прогнозирование занятости и экономической ситуации, борьба с преступностью;
- спорт: отбор перспективных игроков и разработка стратегий игры.
Это далеко не полный список областей и способов применения дата сайенс. Количество кейсов абсолютно разной направленности с использованием «науки о данных» растет год от года.
С Data Science сталкиваются не только специалисты, работающие в этой области, но и простые пользователи интернет-сайтов и сервисов. Это связано с тем, что в них применяются инструменты науки о данных. Допустим, известный аудио-сервис Spotify использует их в рамках оптимизации подбора музыкальных композиций для пользователей в соответствии с их предпочтениями.
Это касается и видео-стримингов вроде Netflix, которые стараются предложить своим зрителям релевантный их интересам контент. Uber активно изучает данные, для того чтобы прогнозировать спрос, повышать качество своих продуктов, автоматизировать рабочие процессы.
Только до 4.05
Скачай подборку тестов, чтобы определить свои самые конкурентные скиллы
Список документов:
 Тест на определение компетенций
Тест на определение компетенций
Чек-лист «Как избежать обмана при трудоустройстве»
Инструкция по выходу из выгорания
Чтобы получить файл, укажите e-mail:
Подтвердите, что вы не робот,
указав номер телефона:

Уже скачали 7503
Рассчитывать исключительно на результаты Data Science не стоит, однако в ней есть крайне полезные инструменты, которые позволяют бизнесу лучше ориентироваться в своей сфере и примерно прогнозировать будущее.
Кто такой специалист по Data Science
Датасаентист – это специалист, который занимается обработкой массива данных, извлечением из них полезной информации, нахождением взаимосвязей и закономерностей, используя алгоритмы машинного обучения. Модель представляет собой алгоритм, который можно использовать для решения бизнес-задач.
Например, в Яндекс.Такси модели создаются для прогнозирования спроса, подбора оптимальных маршрутов, контроля состояния водителей. Удачное использование моделей позволяет снижать стоимость поездок и повышать качество услуг. В банковской сфере с помощью модели можно оптимизировать процесс принятия решения о выдаче кредита потенциальному заемщику.
В страховых компаниях они помогают оценивать вероятность наступления страхового случая. Тем, кто продает свои товары онлайн, внедрение модели может помочь увеличить рекламную конверсию.
Data Science используется в глобальных поисковых системах, сервисах рекомендаций, в работе голосовых помощников, автономных поездов и автомобилей, сервисах распознавания лиц и многом другом.
Следует отличать датасаентиста от аналитика данных. Аналитик data science в процессе своей работы анализирует информацию и в результате выдает модель или код, написанный на основе этого анализа. Его основная задача лежит в технической плоскости, он скорее инженер. Аналитик данных занимается решением бизнес задач, для чего он изучает нужды потребителей, анализирует информацию, тестирует гипотезы и визуализирует результат.
Датасаентист работает с помощью машинного обучения. Он создает модель по выданному ему техническому заданию. Она должна обеспечить определенный результат.
Задачи специалиста по Data Science
Data science аналитик данных в каждой компании имеет свои задачи. В крупных корпорациях он, как правило, отвечает за несколько направлений деятельности. Если это банк, датасаентист может заниматься вопросами оценки заемщиков и распознавания речи.
Рассмотрим стандартные этапы рабочего дня специалиста в области Data Science. Как правило, их пять.
- Сбор информации. Информация разного рода (структурированная и неструктурированная) собирается из разных источников, которые являются релевантными поставленной задаче и области деятельности. Методы работы разнообразны – это и ручной ввод, и скрапинг веб-страниц, и сбор данных из проприетарных систем.
- Хранение информации. Специалист ищет способы хранения собранной информации, которые позволят в дальнейшем заняться ее обработкой с использованием уже имеющихся специальных инструментов. На этом этапе происходит фильтрация данных, удаление дублей и т.п.
- Предобработка. Происходит предварительный анализ собранных данных и выявление наиболее заметных взаимосвязей между ними. Кроме того, на этом этапе необходимо проследить паттерны, проверить реальность информации и ее соответствие решаемым задачам.
- Обработка. Собранные данные обрабатываются с помощью специальных инструментов датасаентиста. Он использует искусственный интеллект, модели машинного обучения, аналитические алгоритмы и т.д.
- Коммуникация. Специалист визуализирует результаты работы, создавая таблицы, графики, списки и т.п. Форма подачи данных выбирается в зависимости от конкретной ситуации, выполняемых задач и категории потребителей информации.


Читайте также
Несмотря на то, что работа датасаентистов в каждой сфере деятельности строится по определенным уникальным правилам, есть и общие для всех областей черты. Практически каждый специалист должен:
- определить задачи, которые хочет решить заказчик;
- выяснить, насколько целесообразно решать рабочий вопрос с использованием методов машинного обучения;
- собрать, обработать данные, разметить, подготовить их к дальнейшему использованию;
- определить метрики оценки эффективности модели;
- разработать и протестировать модели машинного обучения;
- доказать прогнозируемый экономический эффект от внедрения модели;
- внедрить модель в бизнес-процессы;
- сопровождать модель в процессе ее использования.
Статистика для data science имеет большое значение. Ее сбор происходит постоянно, этапы работы повторяются для уточнения данных и совершенствования моделей.
Использовать инструменты Data Science можно в рамках бизнеса любого масштаба. Разница в размерах команды и масштабе решаемых задач. Основной объем работы – у руководителя проекта. Он поддерживает контакт с заказчиками, получает четкое ТЗ, а потом ставит задачи подчиненным (аналитикам разного уровня). Датасаентист, работающий в одиночку, может и общаться с заказчиками, и выполнять поставленные перед ним задачи.
Собирать данные также могут как несколько специалистов, так и один – все зависит от уровня компании и масштабов отдела аналитики. При этом как правило используются инструменты, упрощающие и автоматизирующие этот процесс. Они также помогают предварительно фильтровать и систематизировать полученную информацию.
Разметка данных — важный этап работы аналитика. Метка, которая присваивается каждой записи, помогает определять класс данных. Например, так можно пометить спам или уровень платежеспособности клиента банка. Обычно это делается вручную, так как в данном случае очень важно итоговое качество работы.
Довольно частая ситуация – получение разрозненной информации от заказчика. Ее нужно обработать, структурировать, найти взаимосвязи и закономерности. Для этого нередко используется пайплайн — стандартная последовательность действий в ходе анализа данных. У каждого специалиста она своя.
Как правило, в процессе считывания информации аналитик выдвигает гипотезы, которые потом нужно проверять. Данные необходимо перевести в формат, удобный для машинного обучения. Это позволяет запустить «пробное» обучение и проверить выдвинутые гипотезы. Если они не подтверждаются, этот набор данных больше не используется в работе.
Когда какая-то гипотеза (или несколько гипотез) находит подтверждение, получается первая (baseline, или базовая) версия модели. На ней будут строиться последующие итерации, которые могут привести к улучшению самой модели. Это тот продукт, который уже можно продемонстрировать заказчику, протестировать и развивать дальше.
Создавая модель, определяют и метрики, позволяющие впоследствии оценить ее эффективность. Как правило, создают два типа метрик: для бизнеса и технические. Первые дают возможность отследить экономический эффект от внедрения модели, а вторые определяют ее качество (допустим, точность предсказаний).
Необходимо также оценить контролируемость и безопасность полученной модели. Допустим, в медицинской отрасли это имеет ключевое значение, особенно когда речь идет о диагностике. Протестированную модель можно встроить в производственный процесс (например, кредитный конвейер) или продукт (например, мобильное приложение) и отслеживать полученный эффект в реальном времени.
Тестирование имеет огромное значение, так как модель с ошибками может повлечь серьезные проблемы для бизнеса. Так, использование неправильной скоринговой модели приведет к одобрению кредитов людям, которые не имеют возможности систематически возвращать долг. В итоге банк понесёт убытки.
Основные инструменты Data Science
Специалисты Data Science должны иметь теоретическую и практическую подготовку в области программирования и создания приложений, поскольку это расширяет их профессиональный инструментарий и рабочие возможности. Важно знать хотя бы один из двух самых популярных в Data Science языков программирования.
- R. Это язык с открытым исходным кодом и программное окружение для создания статистических вычислений. В нем содержится множество библиотек и удобных инструментов, позволяющих фильтровать данные и совершать их предварительную обработку. R предоставляет широкие возможности для визуализации данных и тестирования созданной модели машинного обучения.
- Python. Универсальный язык объектно-ориентированного программирования. Python data science можно использовать в самых разных направлениях деятельности для работы с данными практически любого формата.

Стоит также упомянуть о таких инструментах датасаентистов, как Apache Spark, Tableau, Microsoft PowerBI. И перечислять их можно еще долго.
Знания и умения, необходимые для старта в Data Science
Сегодня основы data science можно изучить на многочисленных курсах и с помощью профильных книг. Специалист в этой области должен иметь довольно обширные знания в области точных наук, машинного обучения, языков программирования, сбора данных.
Статистика, математика, линейная алгебра
Data science обучение предполагает изучение базового курса теории вероятностей, математического анализа, линейной алгебры и математической статистики. Это необходимо для осуществления грамотного анализа результатов применения алгоритмов обработки данных.
Литература.
- «Практическая статистика для специалистов Data Science», П. Брюс, Э. Брюс. Книга актуальна тем, кто уже знаком со статистикой.
- «Наука о данных с нуля», Дж. Грас. Книга поможет в сжатые сроки освоить новую профессию. Из нее можно почерпнуть знания в области большинства необходимых датасаентисту дисциплин.
- «Нейронные сети. Полный курс», С. Хайкин. Работа, посвященная математической составляющей нейросетей.
Машинное обучение
Машинное обучение, или data science machine learning, дает возможность настроить компьютеры таким образом, чтобы они принимали решения в автономном и автоматическом режиме.
Для освоения Data Science с нуля необходимо изучить три главных раздела машинного обучения.
- Обучение с учителем (Supervised Learning). Дает возможность создать прогноз по заранее размеченным данным. В случае, когда нужно предсказать несколько значений (допустим, отличить изображения парусников от автомобилей и катеров), это задача классификации, а если одно (например, предположить стоимость автомобиля в зависимости от его характеристик) — задача регрессии.
- Обучение без учителя (Unsupervised learning). В данном случае отсутствует разметка данных, результат и способ обработки данных заранее не известны. Так можно искать аномалии (нестандартные транзакции по банковской карте), ошибочные показания датчиков и т.п.
- Обучение с подкреплением (Reinforcement learning). Здесь тоже нет разметки, однако присутствует стимулирование нейросети (положительное или отрицательное) в ответ на какие-то действия. Например, таким образом машины обучаются игре в компьютерные игры вроде Dota 2 или Starcraft II.
Литература.
- «Машинное обучение. Наука и искусство построения алгоритмов, которые извлекают знания из данных» П. Флах. Это книга о методах построения моделей и алгоритмах машинного обучения.
- «Вероятностное программирование на Python: байесовский вывод и алгоритмы», К. Дэвидсон-Пайлон. Работа об алгоритмах обработки данных и развитии аналитического мышления и навыков.
- «Введение в машинное обучение с помощью Python», А. Мюллер, С. Гвидо. Книга заточена на отработку практических навыков МО.
Программировать на Python
Data science machine напрямую связана с программированием. Специалисту в области аналитики данных вполне достаточно (по крайней мере на первых порах) знать один язык и лучше всего начать с Python. Это универсальный и многофункциональный язык с простым синтаксисом, который часто используется для обработки данных.
Литература.
- «Python для сложных задач. Наука о данных и машинное обучение», Дж. Вандер Плас. Книга представляет собой руководство по статистическим и аналитическим методам обработки данных.
- «Python и анализ данных», Уэс Маккинни. Автор рассказывает о применения языка программирования Python в дата сайенс.
- «Автоматизация рутинных задач с помощью Python», Эл Свейгарт. Хорошее пособие для новичков.
- «Изучаем Python», М. Лутц. Универсальный учебник с упором на практику. Подойдет и тем, кто только начинает свой путь в работе с данными, и опытным разработчикам.
Освоив базу Python, можно приступать к изучению библиотек для Data Science.
Основные библиотеки:
- Numpy
- Scipy
- Pandas
Визуализация:
- Matplotlib
- Seaborn

Читайте также
Машинное обучение и глубокое обучение:
- SciKit-Learn
- TensorFlow
- Theano
- Keras
Обработка естественного языка:
- NLTK
Веб-скрейпинг:
- BeautifulSoup 4
Собирать данные
Data Mining — серьезный аналитический процесс, в рамках которого происходит изучение данных. С его помощью можно выявлять скрытые паттерны и таким образом получать новую полезную информацию, которая нужна для принятия решений. Тут речь также идет о визуализации данных.
Литература
- «Технологии анализа данных: Data Mining, Visual Mining, Text Mining, OLAP» В.В. Степаненко, И.И. Холод. В книге приведены основные методы обработки данных с примерами.
- «Data mining. Извлечение информации из Twitter, LinkedIn, GitHub», М. Рассел. М. Классен. Пособие по анализу данных на примере социальных сетей с практическими советами.
Тем, кто заинтересовался сферой Data Science, имеет смысл пройти профильные курсы в онлайн режиме – например, в школе GeekBrains – после чего отправиться на стажировку в компанию для получения практических навыков.

Прежде чем искать работу, можно поучаствовать в открытых проектах или соревнованиях. Это позволит определить свой уровень знаний и умений и протестировать профессиональные навыки.